HTTP/2介绍
gRPC系列文章(一)

.. toc::
HTTP/2是HTTP/1的升级版,在完全保留HTTP语义的基础上优化了连接延迟,这篇文章将详细的介绍HTTP/2的工作原理。
基础概念
在HTTP/2中完全使用了二进制传输方案,完全放弃了可读性,但带来了巨大的效能提升。为什么二进制传输方案会带来能效提升的问题我们稍后讨论,但是需要明确的是不管多少的HTTP请求,client和server都只建立一条TCP连接,比如"GET localhost/a.html"和"GET localhost/b.html"都是在同一个TCP链路上被传送。
流(Stream)是指一个双向数据流通道[1][2]。流是一个逻辑上的概念[3],在一次HTTP请求的request和response在同一个流上传递,而TCP连接是复用的,这导致一个物理连接内承载不同流的数据,因此每一个流都会被分配一个ID用于区分数据是属于哪个流的。同时,双向意味着不仅仅client可以向server发送信息,server也能向client发送信息。(这里与主动推送能力的概念还是有分别的。)由客户端建立的流的ID都是奇数的,由服务端建立的流的ID都是偶数的。
**信息(Message)**是指一个request或者response的全部数据。
**帧(Frame)**是传输的最小单位,一般来说一个信息由一个或多个帧组成。
帧(Frame)
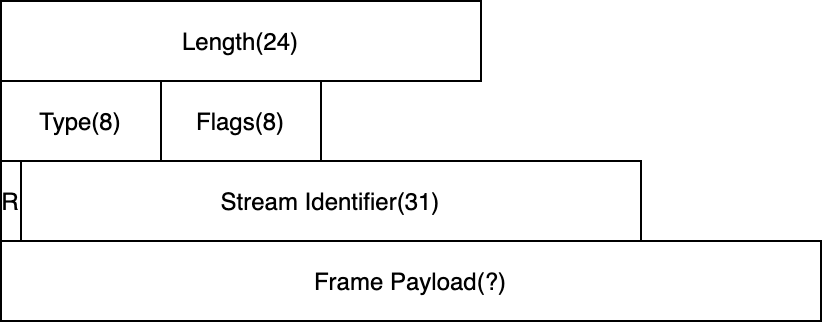
一个数据帧如上图所示,主要有6个部分组成:
- Length:帧长度,默认长度为16KB;
- Type:帧类型,比如传输HTTP Headers的HEADER帧,传输数据的DATA帧等等;
- Flags:标识位,根据帧类型的不同含义不同;
- R:暂时忽略
- Stream Identifier:流ID,一个帧要么属于一个流,要么属于整个TCP连接(ID为0x0);
- Frame Payload:根据Type有不同的格式。
DATA帧
DATA帧的Type为0x0,重要的DATA帧中Flags的含义:
- END_STREAM(0x1):告知接受者没有数据要发送了,流进入关闭状态或半关闭状态;
- PADDED(0x8):表示在Payload中启用填充数据。

Payload的结构比较简单,虚线部分都是与Padding相关的内容,如果Flags的PADDED位置0,则虚线数据都不存在,反之则则存在。真正的数据结构存在于Data部分。
HEADER帧
HEADER帧的Type为0x1,重要的HEADER帧中Flags的含义[4]:
- END_STREAM(0x1):标志流结束,比如在gRPC场景下的Trailer Headers,与DATA帧不同的是,携带END_STREAM的HEADER帧依然可以接受CONTINUATION帧[5];
- END_HEADERS(0x4):表示这个帧包含了全部的header block,不会再有CONTINUATION帧了;
- PADDED(0x8):与DATA帧的PADDED标识含义相同;
- PRIORITY(0x20):表示Exclusive Flag (E)、Stream Dependency和Weight fields存在,稍后介绍。

所有的Headers都包装在Header Block Fragment中,由于HPACK机制不同的Header状态传输的数据也都不同。
(不同的HEADER格式暂略)
多路复用
HTTP/2正是利用多路复用机制才能极大的降低延迟,在本节中先与HTTP/1进行对比,然后再详细的介绍多路复用机制的原理。
我们假设有2个请求的情景,我们将会分别讨论HTTP/1.0、HTTP/1.1和HTTP/2的请求过程。需要一提的是HTTP/2的请求过程图仅供参考。
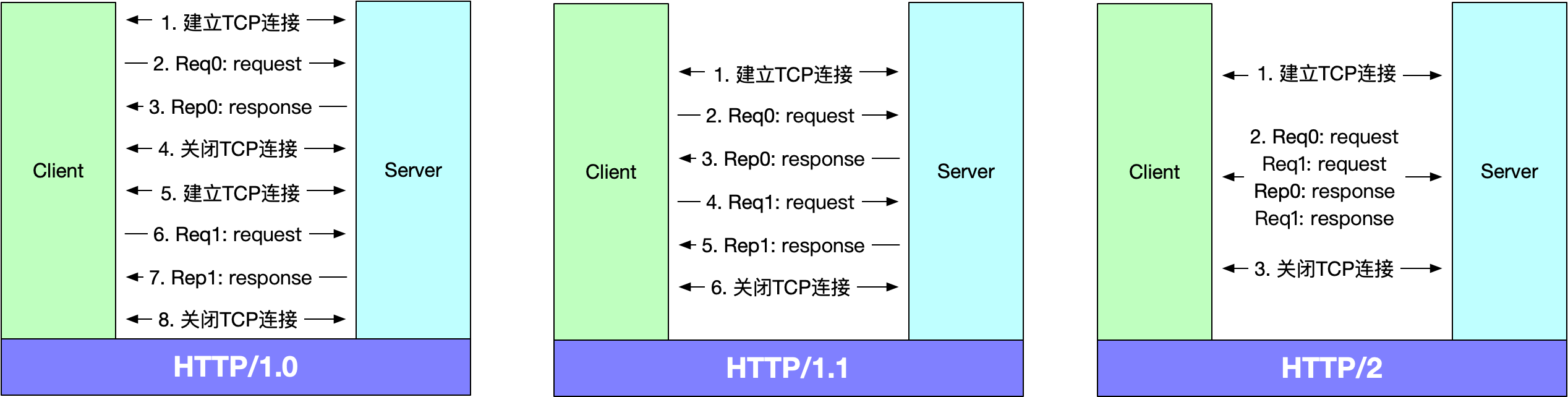
HTTP/1.0是最原始的HTTP版本,也是效率最低的。在上图中可以看到发送两次请求需要建立两次TCP连接,需要经历6次握手过程和8次挥手过程,效率之慢可想而知。HTTP/1.0的问题就出在建立TCP连接次数过多上。
HTTP/1.1引入了keep-alive机制,来解决建立TCP连接次数过多的问题,在上图中可以看到多次请求复用了TCP连接。但是HTTP/1.1的问题是请求需要顺序发送,也是Req1必须等到Req0接收到response之后才能发送,如果Req0非常耗时,那么Req1就会出现饥饿现象。
HTTP/2引入了二进制流,所有数据的传输都基于一个TCP链路,同时一个request或response被分割为若干个帧,帧与帧的传输是完全并行的,不存在HTTP/1.1中Req1需要等待Req0的问题。每个帧都属于一个流或者属于本次TCP连接,即使乱序发射也可以根据流ID进行拼合,所以即使并行发送,也能保证数据完整无误。
头部压缩
HTTP/2中引入了HPACK作为头部压缩策略,通过静态表和动态表实现头部压缩。静态表中存储的是HTTP通用headers,比如Method, URL等等,动态表则是用户自定义的headers,如果一个header是用户自定义的,那么首次到达服务器时会在动态表中分配一个索引。这些表的作用是确定索引与header的映射关系,在表中的header以后就可以使用索引代替字符串,提高传输效率。
如果当前header已经被传输到服务器中且对应的值不变,那么这个值就不需要再次被传输了。一个非常典型的例子是cookie,cookie是一串长度很长的字符串且内容基本不变,在HTTP/2中cookie只会被传输一次,之后将使用索引代替,假设cookie长100bytes,索引长1byte,那么做n次传输就能节省(n-1)*99bytes。
当然头部压缩还有很多细节,在这里就不一一展开了,如果感兴趣可以参考RFC文档。