Project rCore: 进程
操作系统进程总结

.. toc::
这篇文章是来自我完成 rCore OS 章节 5 的总结,在看本篇文章之前你需要先完成 rCore process 的实现。
数据结构
在实现进程这个特性中有几个非常重要的数据结构,先把这些数据结构包含的内容和用途讲清楚之后再梳理整个架构实现。
TaskManager 的定义如下所示,它是一个全局任务等待队列,所有等待执行的 task 都以 TaskControlBlock 的信息存在队列中。
TaskControlBlock (TCB) 保存的是 task 的详细信息,定义如下所示。
TaskControlBlock 包括不可变 (immutable) 和可变 (mutable) 两个部分。不可变部分主要是指 pid 和 kernel_stack,分别表示的是进城 ID 和内核栈。可变的部分就保存在 TaskControlBlockInner 这个结构中。trap_cx_ppn 是指 TrapContext 的物理页框。task_status 表示进程当前的状态,在进程处于 TaskManager 的等待队列的时候其状态为 Ready,在进程正在运行的时候其状态为 Running,在进程退出但是资源没有被完全回收的时候其状态为 Zombie,关于这个状态我们将在稍后的位置再仔细说明一下。parent 和 children 是维护进程树结构的关键。exit_code 则是保存程序的退出码,供父节点了解子程序的退出状态。
Processor 负责管理正在运行的进程,数据结构定义如下所示。
current 就很好理解了,它表示的是当前正在运行的进程的 TCB,idle_task_cx 这个就非常有趣了,它存储的是空闲控制流 (idle control flow),这个也会在稍后详细介绍。
架构
为了方便描述我们将模型简化后绘制在下图中。全局只有一个队列 ready_queue,它存放着当前系统中全部等待执行的任务 (TCB),Processor::run_task() 是一个 fetch loop,不断轮训 ready_queue 中是否有 TCB,如果有则切换上下文让进程运行在 CPU 中,直到时间片耗尽或者进程主动退出,CPU 交还给 fetch loop 进行下一次的进程调度。在这个简易实现的版本中假定只有一个 CPU 核心,否则有多个 Processor 实例同时运行 fetch loop。
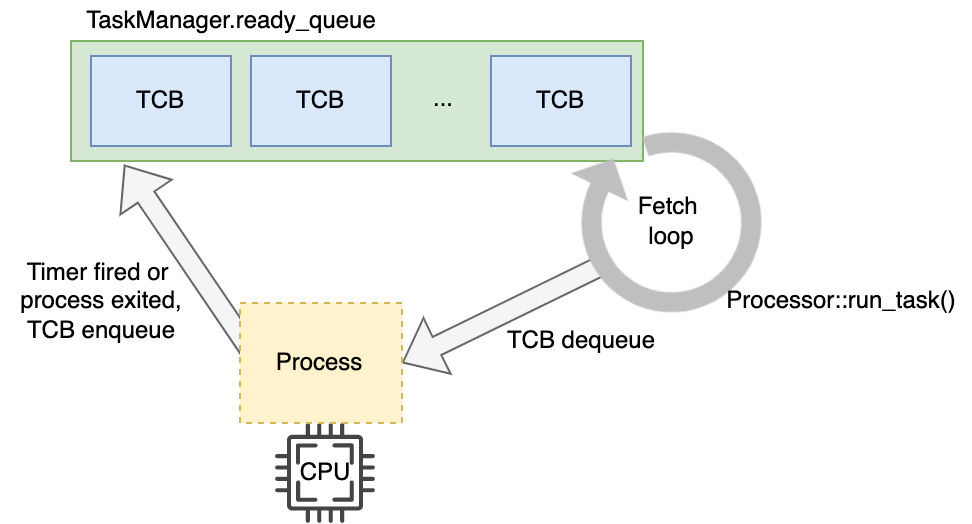
可以看到整个过程并不复杂,但是要是想实现这个功能需要注意的细节还是比较多的,在本篇文章中我们着重会讨论以下几个内容:
- Idle control flow & fetch loop
- Initproc process
- Syscall: fork, exec & waitpid
Idle Control Flow & Fetch Loop
前置知识:需要知道进程之间是如何在内核态切换任务的,可以参考的内容是 Q&A::问题二 和 rCore: 多道程序与分时多任务。
在实现进程特性之前,全部进程都只运行一次且在操作系统编译之前已经确定了运行顺序,统一放置在一个队列中等待调度和执行,在执行的过程中并不存在操作系统等待下一个进程 (fetch loop) 这个环节,系统的进程流向如下图左半部分所示。
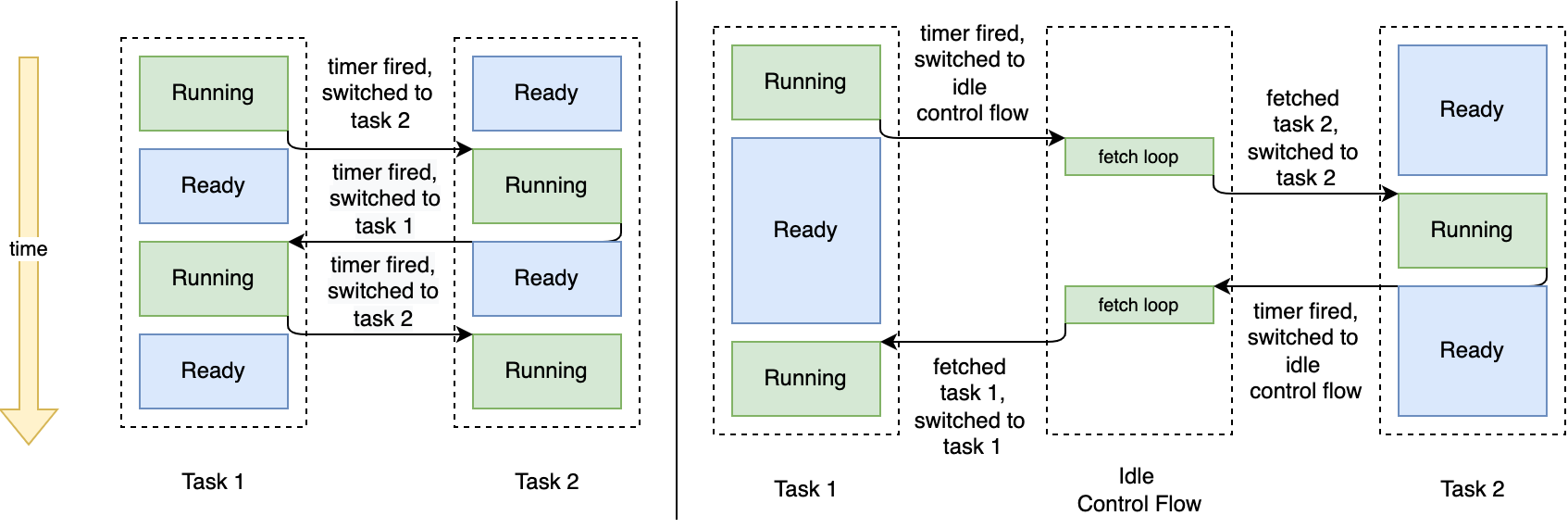
引入进程特性之后系统的不确定性增加了:操作系统不能在运行之前确定进程的运行顺序,甚至无法知道进程是在什么时候被启动的(进程是由用户通过 shell 启动),所以原有的进程流已经不在适用现在的情况。为了简化整体调度和切换流程,idle control flow 就被引入到操作系统中了。当前进程交出 CPU 使用权后,可能是因为时间片用尽,也可能是因为程序退出,统一由 idle control flow 的 fetch loop 从全局队列中获取下一个运行进程,如上图右半部分所示,从结果上来说简化了流程,增加了耗时。
Idle control flow 是如何切换的呢?
回看 Processor 这个数据结构有一个 idle_task_cx 字段,该字段和每个进程的 task context 的作用是一样的,在从 idle control flow 切换到其他任务的时候会保存当前 fetch loop 的现场(保存 sp、ra 以及 callee 寄存器数据),反之在其他任务交出 CPU 使用权后又会通过 idle_task_cx 恢复 fetch loop 现场(恢复数据到上述寄存器中)。我们可以把 fetch loop 过程视为一个特殊的任务,但是它不单独占有一个 TCB,也就是没有 PID、内存空间等等,它仅仅出现在内核空间中。
Initproc 进程
rCore 在内核加载完毕后会首先加载一个 initproc 进程用于操作系统的初始化的工作,在传统的 Linux 操作系统中与 init 进程作用相仿,通常初始化进程的 PID 为 1。在我们的实现中,initproc 进程做的事情非常简单,就是 fork 并 exec 了一个新进程 "user_shell",此后操作系统的控制权就移交给新的子进程 "user_shell" 等待用户提交进程,原进程则调用 waitpid syscall 阻塞等待直到所有进程结束。
流程上非常简单,但是我这里想补充一些现行 Linux 发行版中的 systemd 关键进程,他的目标是代替原有 init 进程接管操作系统初始化的工作,这样会有四个优势“尽可能启动更少的进程”、“尽可能将进程并行启动”、“跟踪和管理进程的生命周期”以及“统一管理服务日志”,具体的内容可以参考《深入了解 Systemd 之概要介绍》。
Syscall
Fork 和 exec 系统调用是一对“好基友”,他们做的事情就是复制一个子进程 (fork),在子进程中启动一个新的进程 (exec),但是 fork 如何复制一个子进程,exec 又如何启动一个新进程呢?在这个章节将会被详细的介绍。
Fork
从行为上来说,父进程调用 fork 系统调用此时程序复刻了一份为子进程,在父进程中返回子进程的 pid,在子进程中返回 0。做的事情比较简单,但是想要实现这个“简单”的功能,需要考虑的点有很多。
问题一:子进程和父进程的相同和不同点是什么?
- 相同的是:虚拟地址。
- 不同的是:pid、kernel stack(内核栈)、task context、trap context、物理地址。
Pid、kernel stack、task context 以及 trap context 都是创建一份新的,根据子进程的需要去填充数据,并不会有什么难以理解的点,详细的内容和实现请参见 rCore 源码。
相比之下,设计比较巧妙的是地址空间,他们在虚拟地址层面相同,但是在物理地址层面又不相同,这应该如何理解呢?首先,物理地址不同是肯定的,如果物理地址都相同的话,又怎么说子进程和父进程是两个不同的程序呢?为了说明虚拟地址是相同的问题,在下面会贴出来一段代码来描述 fork 是如何被使用的。
在调用 fork 系统调用后,子进程和父进程需要在相同的代码段执行判断,如果虚拟地址不同的话那么 fork 调用结束后 ra 寄存器将无法正确定位到这个 if 语句中。
实现起来其实也非常简单,就是遍历父进程的全部页表项,为子进程创建一个新的物理页帧的同时,复制数据以及虚拟地址和物理地址的映射关系,具体代码逻辑参考 src/mm/memory_set.rs 的 MemorySet::from_existed_user() 方法。
问题二:如何才能让父进程和子进程 fork 返回的数据不一样?
Fork 的逻辑都是在内核态完成的,那么用户获得的返回值都是保存在 TrapContext 的 x[10] 的位置中,具体可以参见 《rCore 第二章:批处理系统》。也就是在内核执行完 fork 操作后,将 child 的 TCB 中的 pid 获取后,修改子进程的 x[10] = pid ,设置当前进程的 x[10] = 0 就能实现该效果。
问题三:子进程是如何被执行的?
在 fork 结束的时候将 child 的 TCB 放置到在 fork 生成子进程后的时候将其 TCB 放置到 TaskManager::ready_queue 的队尾即可。
Exec
Exec 系统调用的功能是运行一个新的进程,如果没有 exec 只有 fork 的话,那么所有进程只都是在模仿父进程。一般都是 fork & exec 一起使用,所以我们继续完善前面的用例。
执行 exec 系统调用需要替换 MemorySet 和 TrapContext。我们选择加载一个新程序的时候,它的数据肯定与当前进程的数据不一样的,换句话说就是它们的地址空间是不同的,更换地址空间就引入了新的 user sp、entrypoint 地址,所以 TrapContext 也需要一起更新,参见 src/task/task.rs 的 TaskControlBlock::exec() 方法。
这里还有一个小细节,由于可能会被 exec 系统调用更新 TrapContext,就是在 trap_handler() 完成 syscall() 之后,必须要重新获取一次当前进程的 TrapContext,避免出现内存访问异常或者返回值不生效的问题,参见 src/trap/mod.rs 的 trap_handler() 方法。
Waitpid
Waitpid 的功能是查询某个/全部子进程退出状态,实现资源完全回收工作,那么完善上面的用例,如下代码所示。
Waitpid 接收两个变量,一个是想要查询的进程 pid,表示查询特定 pid 的进程是否退出,这里比较特殊传入了一个 -1 表示查询是否还有子进程在运行,实现掉用一次查询多个 pid 的效果,exit_code 表示该进程的退出码。Waitpid 的返回值表示当前已经彻底退出的进程 pid,或者 -1 表示目前已经没有子进程正在运行了,或者 -2 表示当前还有子进程正在运行。
“资源完全回收”能看出来两个意思:(1)资源的完全回收是由父进程掉用的 waitpid 系统调用完成的。(2)在之前 waitpid 之前可以实现部分资源的回收。子进程退出的时候只能清楚用户态的数据(memory set 中的数据),但是不能清楚内核态的数据,比如 kernel stack 等,原因是在退出的时候系统是运行在内核态的,如果这个时候清楚无论如何还会有一些剩余逻辑没有正确执行,比如 exit_current_and_run_next() 最后的切换逻辑,所以进程自己不能完全回收自己,必须要由父进程来回收。
Q&A
进程?线程?协程?
在本人多年的面试经验(其实就是两年)来看,进程、线程和协程基本上是必考问题,热点中的热点,之前背背面经也就是随便糊弄糊弄,不过现在我对整个操作系统运作流程有了更深刻的认识,我现在就以我目前的理解来解答一下这个问题。
First of all,什么是进程?
“开发者说:进程就是跑起来的程序”,这个理解对吗?对,但片面了!从操作系统的视角理解才是关键,操作系统运行一个进程需要为他创建一个地址空间,以实现内存隔离,同时操作系统还要控制进程使用 CPU 的时间(时间片)。进程切换开销大,要切换地址空间(详见我的上一篇文章),保存寄存器信息等等,切换地址空间时还要刷新 TLB,进一步也加剧了因访存造成的性能损失。
我们想象一个多进程程序来回进程切换,这就导致性能低下,所以线程横空出世。
线程的特征是共享内存空间,但每个线程维护自己的栈和控制流,在线程切换的时候不需要更新地址空间等等,相比于进程更轻量。在现代操作系统中,线程是 CPU 的调度单位,所以线程是操作系统可见的和控制的,所以线程的切换需要用户态和内核态之间的切换,依然需要保存和恢复大量的寄存器 [1]。除此之外还有绿色线程,即由用户库自行调度的线程。
协程则在线程的基础上更轻量,是由用户自己的库维护的,这里的自己是指非操作系统的组件,比如用户库、编译器等。和线程的区别是共享线程的栈,一个线程内的协程是串行运行的。
那么 goroutine 是线程还是协程呢?
Goroutine 既不属于线程也不属于协程,首先每个 goroutine 的堆栈比线程的更小且可扩展(线程的堆栈是固定的),对比协程 goroutine 之间又是并发的,所以 goroutine 是一种协程的升级版本。