SGEMM CUDA 算子初探
介绍 SGEMM_CUDA 的 Naive Kernel、Global Memory Coalescing Kernel……

SGEMM_CUDA 是一个 SGEMM 算子从 0 到 1 优化的教程,配套文字版教程在「How to Optimize a CUDA Matmul Kernel for cuBLAS-like Performance: a Worklog」。这里会按照一个新手的视角,结合上面的教程重新写一篇入门教程。
SGEMM 的全称是 Single precision GEneral Matrix Multiply,计算 $C = \alpha AB + \beta C$,精度是 fp32。NVIDIA cuBLAS (Basic Linear Algebra Subprograms) 提供了极致的优化算法,SGEMM_CUDA 的目标是一步步优化实现其 95% 的性能。
如果你不熟悉 GPU 架构和 CUDA 编程,强烈建议阅读「CUDA Programming Guide」。
理论极限
计算 $C = AB + C$,其中矩阵 A、B 和 C 的尺寸是 $4092 \times 4092$。
计算
总计算量 FLOPs (Floating Point Opertions) 可以被拆解为 $AB$ 计算量加 $+C$ 计算量。
P.S. 英文原文中错误使用了 FLOPs 和 FLOPS,前者表示的是总计算量,比如一个矩阵运算需要多少次运算,后者(FLoating-point OPerations Per Second)表示的是计算速度,比如 A100 显卡的理论速度为 312 TFLOPS。
$AB$ 矩阵乘,计算每个元素需要用到矩阵 A 的一行,和矩阵 B 的一列,每个元素相加再相乘,一个结果需要的计算量是 $2 \times 4096$。一共 $4092^2$ 个元素需要相乘,最终的计算量是 $2 \times 4096^3$。
$X + C$ 每个元素计算 1 次加法,总计算量为 $4092^2$。
总计算量是 $2 \times 4092^3 + 4092^2 = 137,053,437,840 \approx 137GFLOPs$。
我用的实验卡是 NVIDIA T4,FP32 的理论算力是 8.141 TFLOPS,理论极限运算速度是 137 GFLOPs / 8.141 TFLOPS 约等于 16.828ms。
存储
加载矩阵 A、B 和 C 共需要 $3 \times 4092^2 \times 4B \approx 201MB$,写入矩阵 C 共需要 $4092^2 \times 4B \approx 67MB$。
总存储量是 268 MB,T4 理论带宽速度 320 GB/s,极限存储传输时间为 0.838ms。
Compute-bound
计算时间是传输时间的 20x,可以认为这是一个计算密集型任务(compute-bound)。
Kernel 1: Naive
实现代码
Kernel
__global__ void sgemm_naive(int M, int N, int K, float alpha, const float *A,
const float *B, float beta, float *C) {
// compute position in C that this thread is responsible for
const uint x = blockIdx.x * blockDim.x + threadIdx.x;
const uint y = blockIdx.y * blockDim.y + threadIdx.y;
// `if` condition is necessary for when M or N aren't multiples of 32.
if (x < M && y < N) {
float tmp = 0.0;
for (int i = 0; i < K; ++i) {
tmp += A[x * K + i] * B[i * N + y];
}
// C = α*(A@B)+β*C
C[x * N + y] = alpha * tmp + beta * C[x * N + y];
}
}
启动 kernel
dim3 gridDim(CEIL_DIV(M, 32), CEIL_DIV(N, 32), 1);
dim3 blockDim(32, 32, 1);
sgemm_naive<<<gridDim, blockDim>>>(M, N, K, alpha, A, B, beta, C);
CUDA 代码显示的是一个 thread 的视角。

这里 blockIdx.x * blockDim.x 找到当前 thread 的 block 在 x 轴的起点,blockIdx.y * blockDim.y 找到 block 在 y 轴的起点。
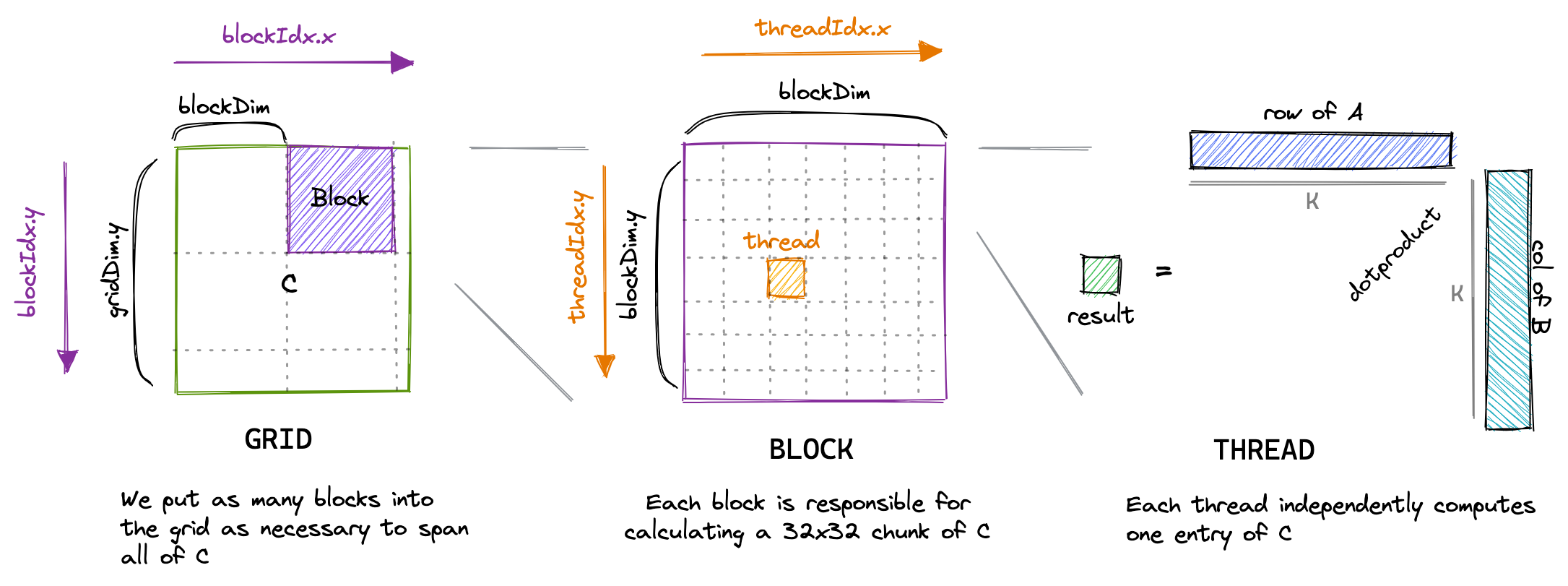
找到 block 的第一个元素的坐标后,就可以通过 threadIdx.x 和 threadIdx.y 定位到矩阵 C 的坐标。Kernel 1 的每个 thread 计算一个矩阵 C 的元素。
2D 数组在这篇教程中会被展开为 1D 数组,左边是逻辑上的样子(2D),右边是物理上的(1D)。

对于一个线程来说,x 是固定的,矩阵 A 的 shape 是 (M, K),所以 x * K 就固定在某一行,x * K + i 遍历一行的全部数据。同理,+ y 是固定的,可以理解为列是固定的,每次加 i 个 矩阵 B 的行长(N),i * N + y 表示遍历一列的全部数据。
实验结果
T4 测试结果如下表,理论算力 8.141 TFLOPS,性能达成率 ~1.95%。
| Size | Average (s) | GFLOPS |
|---|---|---|
| 128 | 0.000243 | 17.2 |
| 256 | 0.001868 | 18.0 |
| 512 | 0.007006 | 38.3 |
| 1024 | 0.035274 | 60.9 |
| 4092 | 0.865349 | 158.4 |
Kernel 2: Global Memory Coalescing
Warp 和 Warp Scheduler
NVIDIA GPU 定义相邻的 32 个 threads 为一组 warp,它们按照 SIMD 方式运作,即同一个指令,不同的数据。
每个 SM 有 4 个 warp schedulers,warp redisent 则更多,同一时间最多有 4 个 warps 并行执行。Warp 的状态分为 waiting 和 ready,前者可能在等 global memory 等。只有处在 ready 状态的 warp 可以被执行。
相邻的 32 个 threadId 被认为是一个 warp,threadId 的计算方式是 threadId = threadId.x + blockDim.x * threadId.y + blockDim.y * blockDim.x * threadId.z。
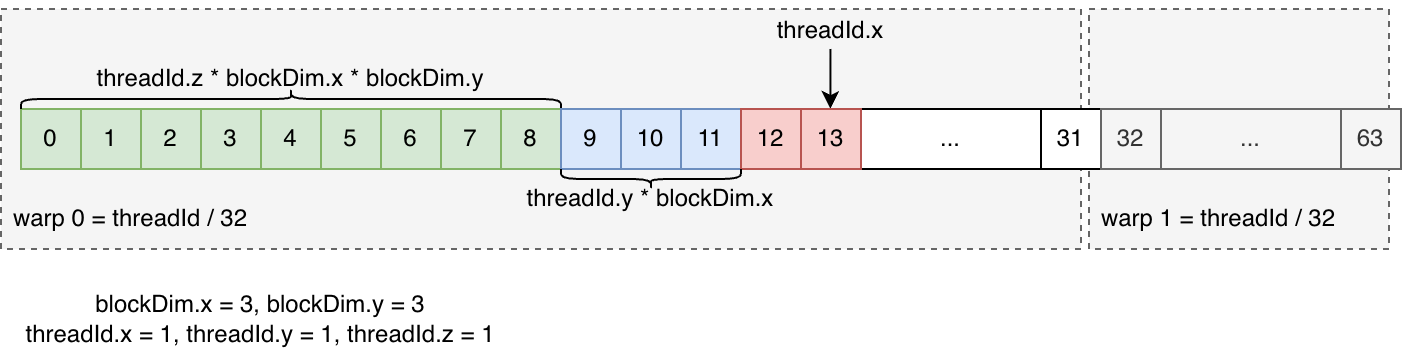
其中 blockDim.y * blockDim.x 表示一个 z 轴长度,* threadId.z 表示跨越了几个 z 轴长度(绿色部分),blockDim.x * threadId.y 表示跨越了几个 y 轴长度(蓝色),最后红色表示 x 内的长度。
Warp ID 的计算方法是 warp = threadId / 32。
Coalescing
当一个 warp 内的 threads 读取一块连续的空间,访存可以被组合为一次 LOAD,这称之为 coalescing。GPU 通常支持 32B、64B 和 128B 内存访问。比如,连续读取 32bits float 时,warp scheduler 可以用一次 LOAD 读取 32 个 floats(32 * 4B = 128B)。
- Coalescing 必须要内存对齐。
- Warp 内的读取顺序无要求,整体是连续的即可。

改进思路
这张图解释了 Naive Kernel 性能不佳的原因。
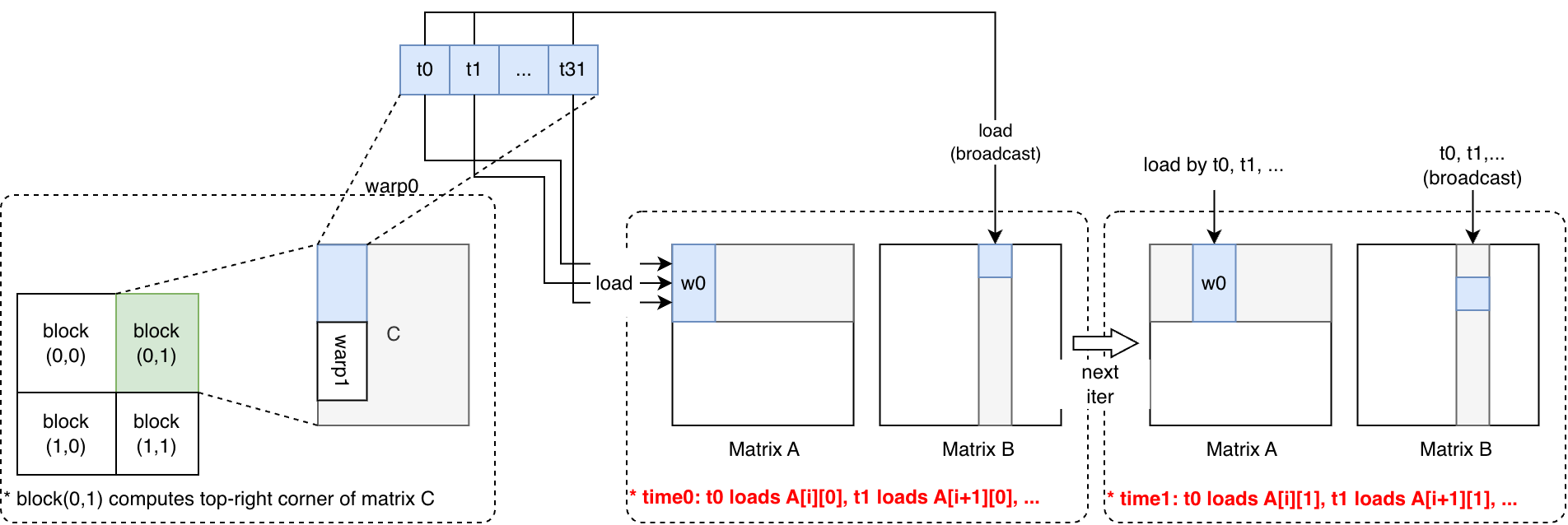
假设 block(0,1) 计算矩阵 C 的右上角,第一个 warp(warp0)负责计算矩阵 C 的一列。右半部分以时间维度展示了 warp0 的线程在同一时间加载矩阵 A 的不同列,time0 t0、t1 分别读取 A[i][0]、A[i+1][0],无法通过 coalescing 连续加载 floats。
根因是 warp 的 threads 计算矩阵 C 不同行元素,改进思路是使其计算矩阵 C 的同一行。
实现代码
Kernel 实现
const int x = blockIdx.x * BLOCKSIZE + (threadIdx.x / BLOCKSIZE);
const int y = blockIdx.y * BLOCKSIZE + (threadIdx.x % BLOCKSIZE);
if (x < M && y < N) {
float tmp = 0.0;
// K loop
for (int i = 0; i < K; ++i) {
tmp += A[x * K + i] * B[i * N + y];
}
C[x * N + y] = alpha * tmp + beta * C[x * N + y];
}
启动 kernel,blockDim 变为 1D,共计 1024 个 threads。
dim3 gridDim(CEIL_DIV(M, 32), CEIL_DIV(N, 32));
dim3 blockDim(32 * 32);
sgemm_coalescing<<<gridDim, blockDim>>>(M, N, K, alpha, A, B, beta, C);
矩阵 C 被分割为 (32, 32) 的 tiles,每个 block 计算其中一个 tile。

再进一步看 block(0, 0) 内部,共计有 32 个 warps 和 1024 个 threads。每个 thread 计算矩阵 C 的一个元素,比如下图标红的 t0 计算 C[0][0]。C[0][0] = A[0][0]*B[0][0]+A[0][1]*B[1][0]+...+A[0][K]*B[K][0]。每个 thread 内部有 K loop 串行计算,thread 之间的计算是并行的。
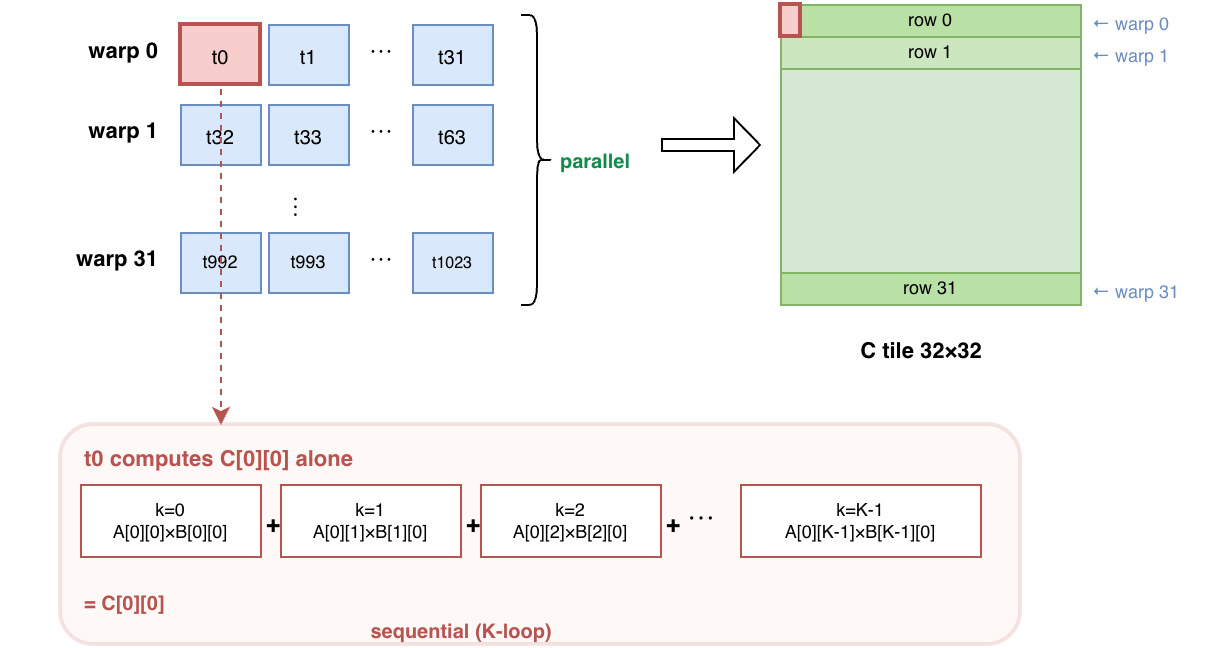
先来看下每个 thread 在做什么
warp0thread0总目标是计算C[0][0],iterk的计算目标A[0][k]*B[k][0]thread1总目标是计算C[0][1],iterk的计算目标A[0][k]*B[k][1]- ...
warp1thread32总目标是计算C[1][0],iterk的计算目标A[1][k]*B[k][0]thread33总目标是计算C[1][1],iterk的计算目标A[1][k]*B[k][1]- ...
下面这张图列举了 k==0 和 k==1 时,threads 访问了哪些矩阵 A 和矩阵 B 的元素。
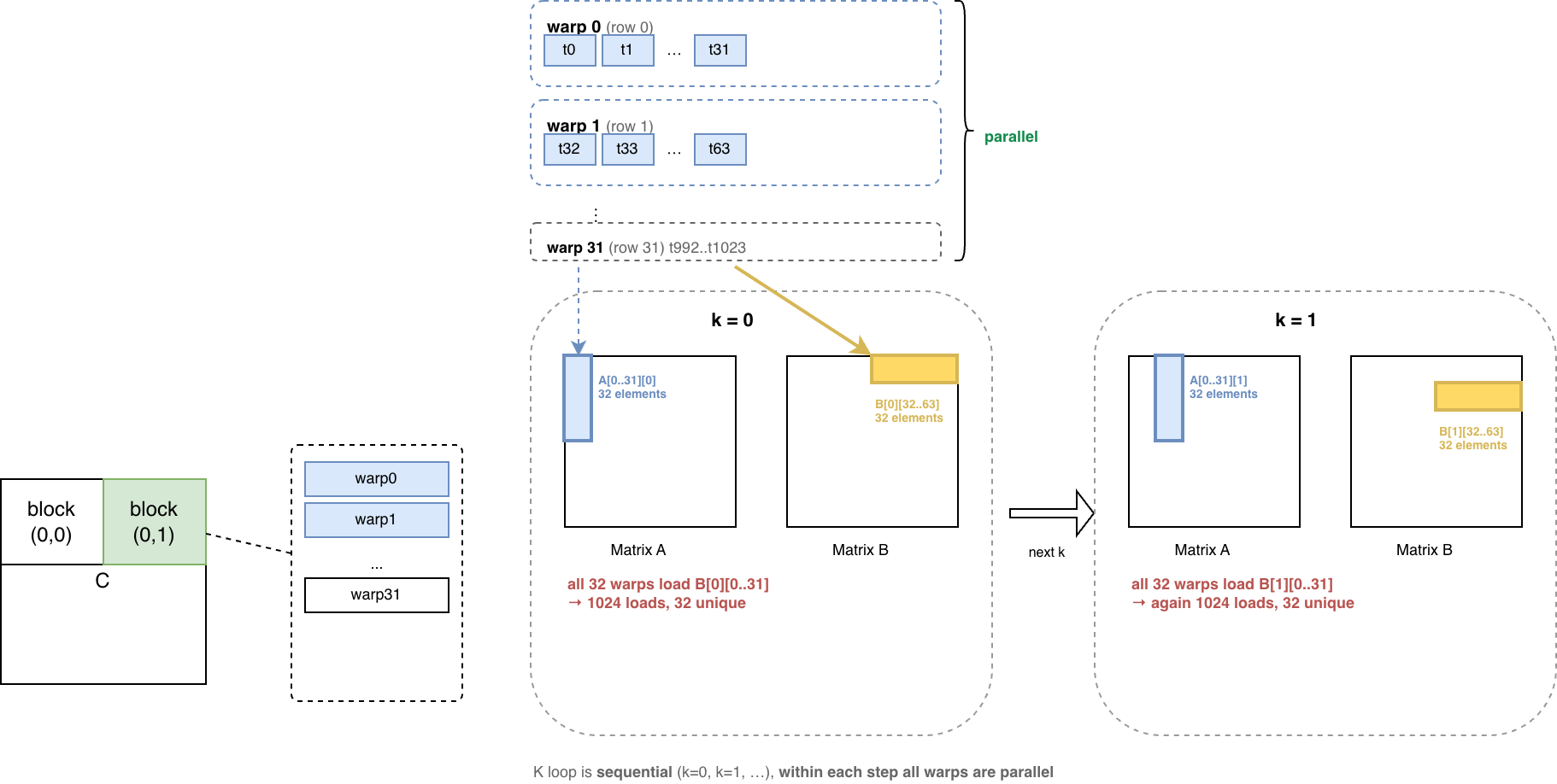
在一个迭代中,一个 wrap 内部:
- 每个 thread 从矩阵 A 中读取同一个元素,broadcast 机制可以高效同步数据到同一个 warp 内的其他的 threads。
- 每个 thread 从矩阵 B 中读取不同的、相邻的元素,warp scheduler 将几个小的 LOAD 请求合并为一个大的请求(coalescing)。
- 临时结果暂存在寄存器(
tmp)中。
K-loop 计算结束后,每个 thread 需要将 tmp 更新到矩阵 C 中不同的、相邻的元素,也可以吃到 coalescing 的红利。
实验结果
4092 size 可以跑出 513.3 GFLOPS 的性能,性能达成率 ~6.31%,比 kernel 1 快了 ~3.24x。
| Size | Average (s) | GFLOPS |
|---|---|---|
| 128 | 0.000038 | 111.4 |
| 256 | 0.000142 | 235.5 |
| 512 | 0.000962 | 279.0 |
| 1024 | 0.004536 | 473.5 |
| 4092 | 0.266998 | 513.3 |
Kernel 3: Shared Memory Cache-Blocking
Shared Memory (SMEM)
每个 SM 物理上有一个 SMEM。每个 block 享有一个 SMEM 的分块(chunk),block 内的线程都可以访问这块区域。速度上 shared memory 远远快于 global memory。比如 A6000 GPU,每个 block 允许访问最多 48KB SMEM。
改进思路
Kernel 2 的问题是矩阵 B 的相同数据被不同的 warps 重复读取了。下图展示了一次迭代 warps 读哪些数据,同一个 block 下面的 warps 都读取了 B[i][0..31] 全部数据,即一个 block 内不同 warp 需要的矩阵 B 的数据是相同的。
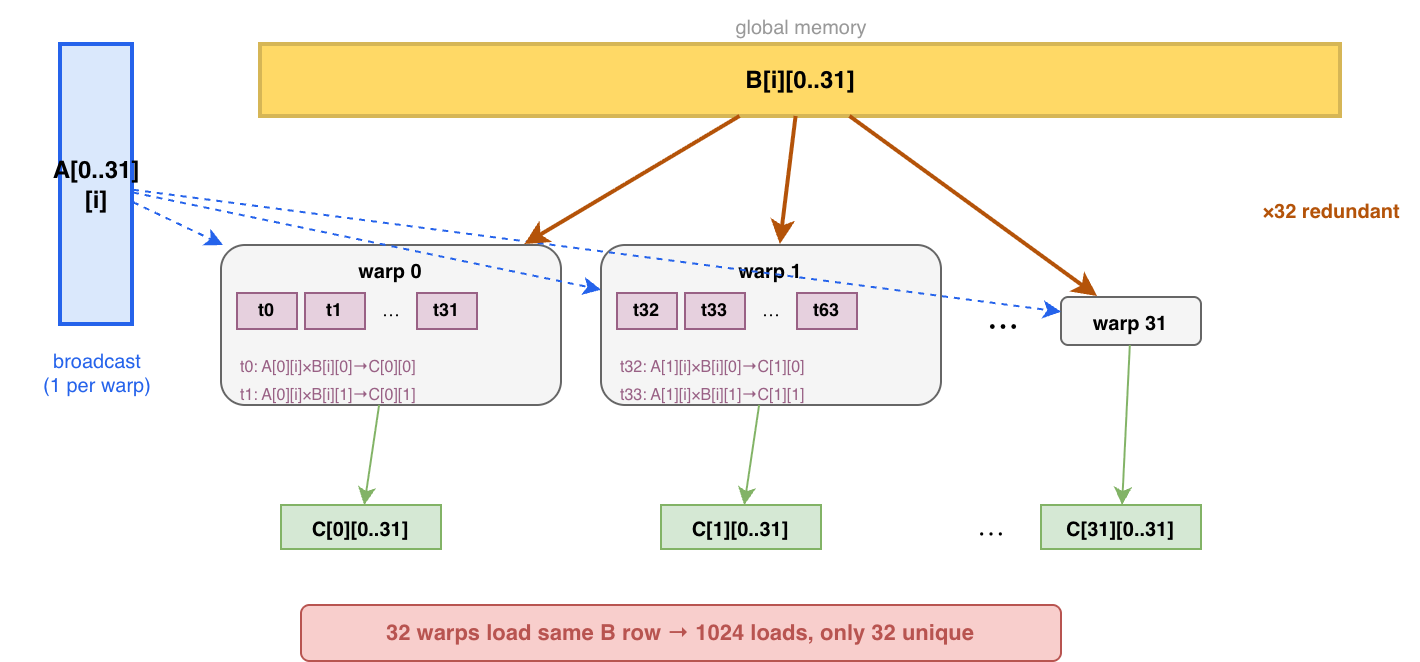
将数据拷贝到 SMEM 可以解决这个问题:
- SMEM 可以在 block 范围内共享,从 GMEM 读一次能用多次
- SMEM 相比 GMEM,延迟更低,速度更快
实现代码
Kernel 代码
__shared__ float As[BLOCKSIZE * BLOCKSIZE];
__shared__ float Bs[BLOCKSIZE * BLOCKSIZE];
A += cRow * BLOCKSIZE * K;
B += cCol * BLOCKSIZE;
C += cRow * BLOCKSIZE * N + cCol * BLOCKSIZE;
float tmp = 0.0;
for (int bkIdx = 0; bkIdx < K; bkIdx += BLOCKSIZE) {
As[threadRow * BLOCKSIZE + threadCol] = A[threadRow * K + threadCol];
Bs[threadRow * BLOCKSIZE + threadCol] = B[threadRow * N + threadCol];
__syncthreads();
A += BLOCKSIZE;
B += BLOCKSIZE * N;
for (int dotIdx = 0; dotIdx < BLOCKSIZE; ++dotIdx) {
tmp += As[threadRow * BLOCKSIZE + dotIdx] *
Bs[dotIdx * BLOCKSIZE + threadCol];
}
__syncthreads();
}
C[threadRow * N + threadCol] =
alpha * tmp + beta * C[threadRow * N + threadCol];
启动 kernel 与之前保持一致
dim3 gridDim((M + 31) / 32, (N + 31) / 32);
dim3 blockDim(32 * 32);
cudaFuncSetAttribute(sgemm_shared_mem_block<32>,
cudaFuncAttributePreferredSharedMemoryCarveout,
cudaSharedmemCarveoutMaxShared);
sgemm_shared_mem_block<32>
<<<gridDim, blockDim>>>(M, N, K, alpha, A, B, beta, C);
Block 持有两个 SMEM,分别是 As 和 Bs,容量都是 32*32 =1,024 个 floats。As 保存矩阵 A 数据,Bs 保存矩阵 B 数据。
假设矩阵 A 的长度是 (4092,4092),计算 C[0..31][0..31] 需要加载 32*4092 个元素,然而 As 只能存 32*32 个数据,因此需要分片加载,如下图所示。
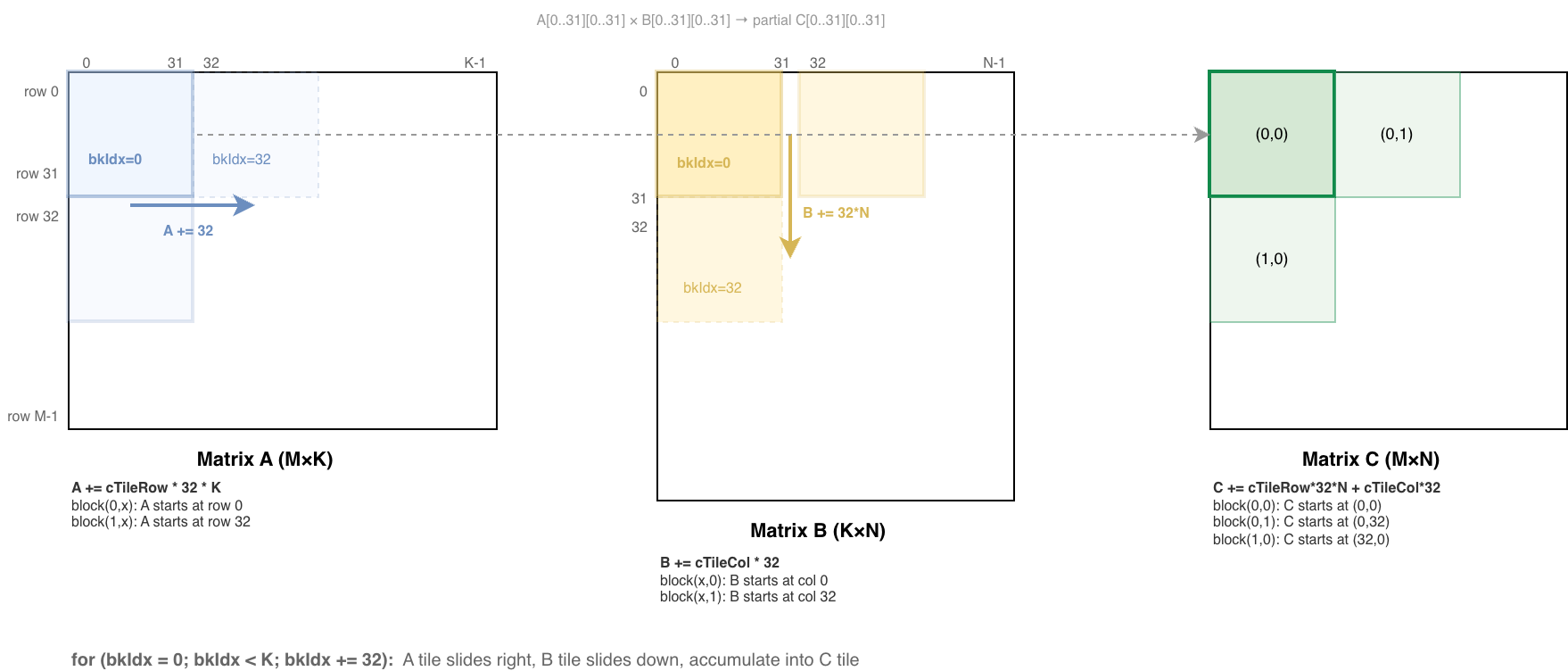
缓存到 SMEM 的步骤:
- Thread 分别从矩阵 A 和矩阵 B 读取一个数据并保存到 SMEM。加载过程中,相邻的 threads 读取相邻的顺序,符合 coalescing 原则。
- 使用
__syncthreads()同步等待其他的 threads 完成任务。这个同步是必须的,否则会出现数据不一致的问题。 - 把矩阵 A 和矩阵 B 指针分别向右和向下移动
BLOCKSIZE长度。
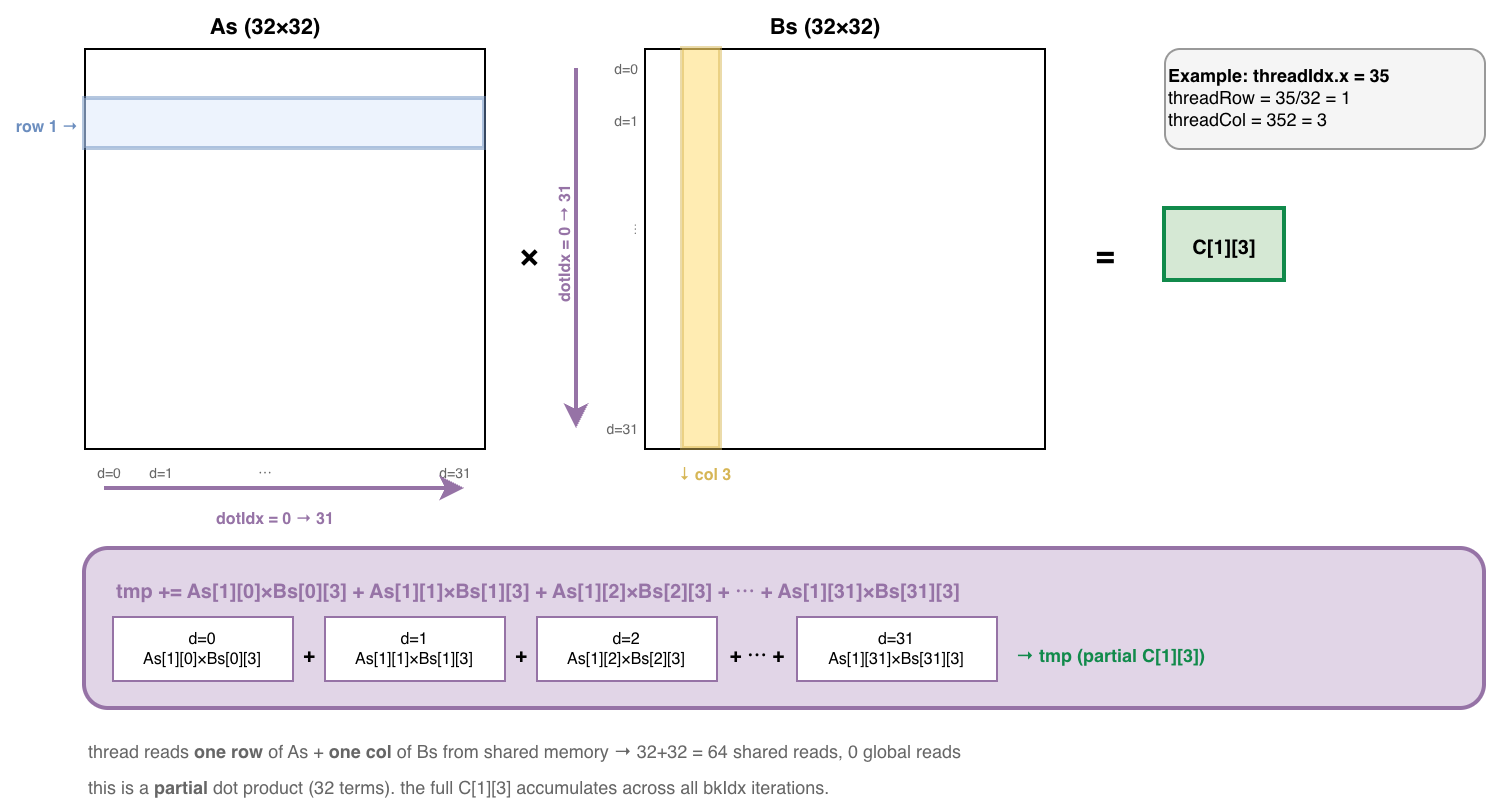
下图展示了计算部分的原理,基本上跟 kernel 2 一致,threads 在 BLOCK_SIZE 个迭代内,各自独立处理 As 的一行和 Bs 的一列。区别是最终得到的 C[1][3] 不完整,因此被保存在 tmp 寄存器中。只有当 SMEM tiling 完全遍历完矩阵 A 和矩阵 B 的时候,才会写回到矩阵 C。
Occupancy
SMEM 的尺寸是有限制的,我是用的 T4 每个 SM 可用的空间只 64KB,不过 CUDA 程序中最多可以使用 48KB。我们使用了 2*32*32*4B=8KB 的 SMEM,距离上限还有一定的距离。
如果一个 block 占满了 SMEM,那么当前的 SM 只能运行一个 block,这影响了 SM 的占用率(occupancy)指标。占用率的计算方法是 occupancy = (active warp num)/(maximum warp num)。占用率高意味着某些延迟可以被隐藏,比如 warp0 在等 GMEM 中的数据,warp1 ready 则被执行,等 warp1 执行完毕时 warp0 数据准备完成进入 ready 状态,warp0 执行,这样就隐藏了访存延迟。这里的逻辑是:如果 block 只能运行一个,那么可供调度的 warp 数量降低,最终影响 occupancy 指标。它被 SM 中的寄存器数量、warp 数量以及 SMEM 容量相关。
为什么跟 warp 数量相关?Warp 数量越多,调度一次的成本就越大,因为管理 warp 不是免费的。比如当前有 32 个 warps 和 512 个 warps,调度器是扫描 32 个 warps 的速度更快。
Kernel 3 的占用率是多少?我的硬件信息如下
Device 0: Tesla T4
Compute capability: 7.5
SMs: 40
Max threads/SM: 1024
Max threads/block: 1024
Max blocks/SM: 16
Warp size: 32
Registers/SM: 65536
Registers/block: 65536
Shared memory/SM: 65536 bytes
Shared memory/block: 49152 bytes
L2 cache: 4194304 bytes
Global memory: 15843721216 bytes (15.8 GB)
Memory bus width: 256 bits
Memory clock: 5001 MHz
Clock rate: 1590 MHz
其中
- 每个 SM 的 SMEM 是 64KB
- 每个 block 最多可以有 1,024 个线程
- 每个 SM 最多有 65536 个 registers
Kernel 3 占用的资源
- Registers per Thread: 46
- SMEM per Block: 8KB
- Threads per Block: 1,024
编译时可以添加 --ptxas-options=-v 获取每个 kernel 占用的资源,显示占用 46 个寄存器。
ptxas info : Compiling entry function '_Z22sgemm_shared_mem_blockILi32EEviiifPKfS1_fPf' for 'sm_75'
ptxas info : Function properties for _Z22sgemm_shared_mem_blockILi32EEviiifPKfS1_fPf
0 bytes stack frame, 0 bytes spill stores, 0 bytes spill loads
ptxas info : Used 46 registers, 8192 bytes smem, 400 bytes cmem[0]
Warp 数选择下面的任意一个
- SMEM: 8KB + 1KB (CUDA runtime usage),每个 block 占用 9KB SMEM。一个 SM 上最多可以运行 (64KB per SM)/(9KB per Block) = 最多 7 Blocks per SM。
- Threads: 一个 SM 最多运行 1024 个线程,最多 1 Block per SM。
- Registers: 一个 warp 占用 (46 regs per Thread) * (32 Threads per warp) = 1,472 regs per warp。Regs 以 256 单位为一组,因此一个 wrap 占用 1,536 个 regs。一个 block 包含 32 个 warps,因此最终需要 49,152 regs per Block。一个 SM 配备 65,536 regs,因此最多一个 block。
最终,只能在一个 SM 上同时跑一个 block,1,024/1,024=1,所以占用率是 100%。(what?? 100%??)
Profiling
过程不展示了,直接看原文吧。
不过原文中提到了 profiling 的结果是 Stall MIO Throttle 占比过大。MIO 全程是 Memory I/O,每个 SM 有一个专有 pipeline unit,与之相关的是 main math pipeline。它的功能是处理一些非数学问题。
MIO pipeline 是一个统称
- shared memory unit (LDS/STS)
- SFU (sin, cos, rsqrt, ...)
- branch unit
- texture unit
它的占比高可能源自这几种可能
- Special math instructions:sin, cos, exp, log, rsqrt,它们是通过快速模拟实现的,因此走 MIO
- Dynamic branches:完成线程的 if/else 功能
- Shared memory instructions: LTS(从 SMEM 中加载)和 STS(存储到 SMEM)
原文提到 kernel 3 没有特殊的数学公式也没有 if/else 分支,因此主要的瓶颈集中在 SMEM 访问上。
实验结果
4092 size 可以跑出 513.3 GFLOPS 的性能,性能达成率 ~11.19%,比 kernel 2 快了 ~1.78x。
| Size | Average (s) | GFLOPS |
|---|---|---|
| 128 | 0.000027 | 154.9 |
| 256 | 0.000109 | 308.2 |
| 512 | 0.000718 | 373.8 |
| 1024 | 0.004174 | 514.4 |
| 4092 | 0.150397 | 911.2 |
Kernel 4: 1D Threadtiling
改进思路
Kernel 3 profiling 章节提到了 MIO stalls 的问题,核心原因是 SMEM 操作和运算操作的比例过高导致的。Kernel 3 从 As 和 Bs 各取了一个 float,然后执行了一次 FMA (Fused Multiply-Add,即 a*b+c),SMEM/FMA 的比例为 2。改进思路是一次 LTS 可以执行更多的 FMA。
实现代码
Kernel 实现
float threadResults[TM] = {0.0};
__shared__ float As[BM * BK];
__shared__ float Bs[BK * BN];
for (uint bkIdx = 0; bkIdx < K; bkIdx += BK) {
As[innerRowA * BK + innerColA] = A[innerRowA * K + innerColA];
Bs[innerRowB * BN + innerColB] = B[innerRowB * N + innerColB];
__syncthreads();
A += BK;
B += BK * N;
// compute outer-loop
for (uint dotIdx = 0; dotIdx < BK; ++dotIdx) {
float Btmp = Bs[dotIdx * BN + threadCol];
// compute inner-loop
for (uint resIdx = 0; resIdx < TM; ++resIdx) {
threadResults[resIdx] +=
As[(threadRow * TM + resIdx) * BK + dotIdx] * Btmp;
}
}
__syncthreads();
}
启动 kernel,一共 512 个线程。
void run_sgemm_1d_blocktiling(int M, int N, int K, float alpha, float *A,
float *B, float beta, float *C) {
const uint BM = 64;
const uint BN = 64;
const uint BK = 8;
const uint TM = 8;
dim3 gridDim((N + BN - 1) / BN, (M + BM - 1) / BM);
dim3 blockDim((BM * BN) / TM);
sgemm1DBlocktiling<BM, BN, BK, TM>
<<<gridDim, blockDim>>>(M, N, K, alpha, A, B, beta, C);
}
矩阵 C 分割从 kernel 3 的 (32, 32) 变为了 (64, 64),线程数量少了一半(1,024 -> 512),As 和 Bs 的容量也少了一半(1,024 -> 512),矩阵 C tile 大了 4 倍(32*32 -> 64*64)。Kernel 3 每个线程处理 1 个矩阵 C 元素,kernel 4 每个线程处理 8 个矩阵 C 元素(TM),线程处理量增加 8 倍。

读取过程如下图,展示了第一轮和第二轮两次加载。每走完一个循环,bkIdx 增加 8,矩阵 A 的指针和矩阵 B 的指针分别向右和向下移动 8 个单位。
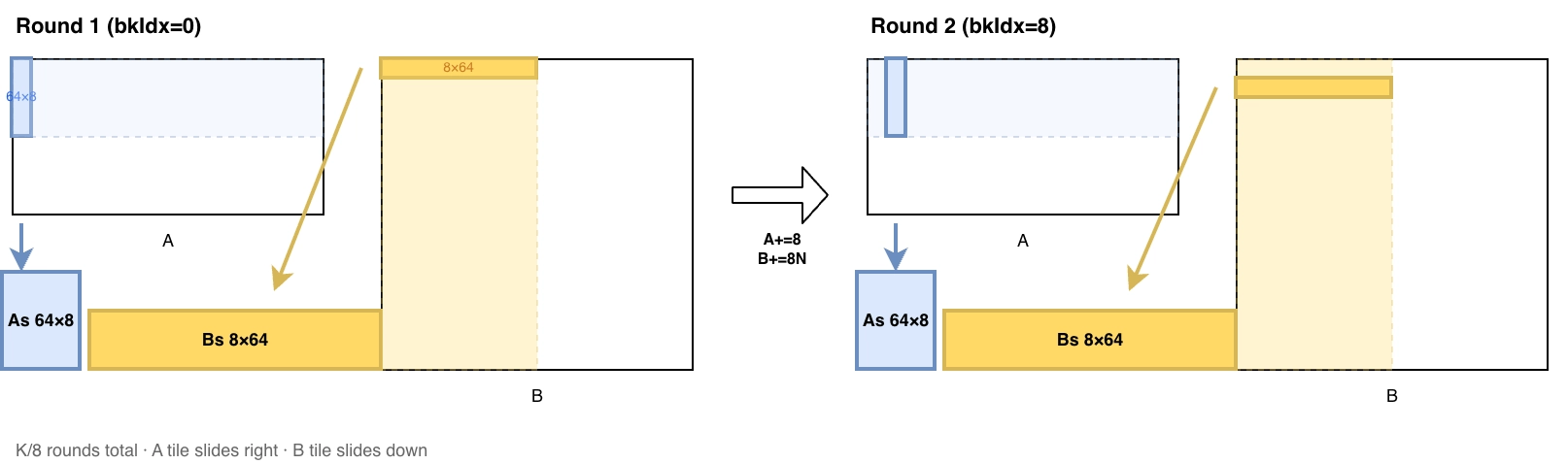
计算一个 64*64 的 C tile 每个线程的计算工作和对应的矩阵 A 和矩阵 B 的列表如下所示
| C tile region | warp | thread | computes | needs from A | needs from B |
|---|---|---|---|---|---|
CTile[0..7][0..63] |
warp 0 | thread 0 | CTile[0..7][0] |
A[0..7][0..4092] |
B[0..4092][0] |
| … | … | … | … | ||
| thread 31 | CTile[0..7][31] |
A[0..7][0..4092] |
B[0..4092][31] |
||
| warp 1 | thread 32 | CTile[0..7][32] |
A[0..7][0..4092] |
B[0..4092][32] |
|
| … | … | … | … | ||
| thread 63 | CTile[0..7][63] |
A[0..7][0..4092] |
B[0..4092][63] |
||
CTile[8..15][0..63] |
warp 2 | thread 64 | CTile[8..15][0] |
A[8..15][0..4092] |
B[0..4092][0] |
| … | … | … | … | ||
| thread 95 | CTile[8..15][31] |
A[8..15][0..4092] |
B[0..4092][31] |
||
| warp 3 | thread 96 | CTile[8..15][32] |
A[8..15][0..4092] |
B[0..4092][32] |
|
| … | … | … | … | ||
| thread 127 | CTile[8..15][63] |
A[8..15][0..4092] |
B[0..4092][63] |
||
| … | … | … | … | … | … |
其中我们可以发现
- 每个 thread 计算 8 个 C tile 元素
- 两个 warps 处理 C tile 的一行
- 处理同一行的 C tile,访问矩阵 A 的数据是一样的,但矩阵 B 不一样(下图左)
- 处理同一列的 C tile,访问矩阵 A 的逻辑行是不同的,但矩阵 B 是一样的(下图右)
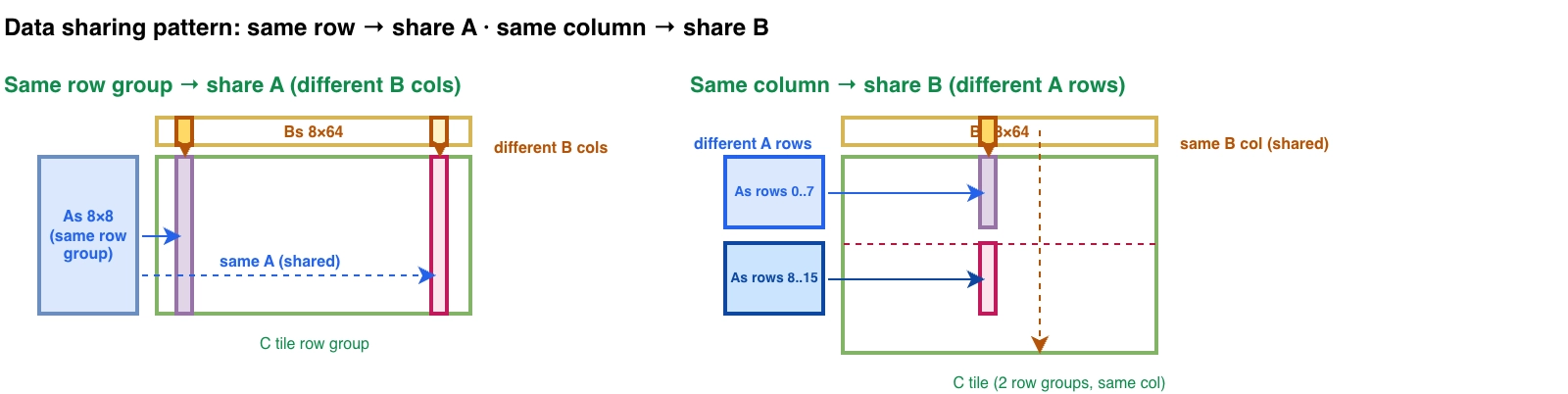
标题所谓的 1D blocktiling 的含义是,处理一个 64*64 的 C tile,可以通过 8*64 个 threads,其中横向的 8 个 threads 每次串行 loop 8 次,实现了计算 64 行,纵向则是每个列单独计算(没有 tiling,kernel 5 会继续把列也加入 tiling,实现 2D blocktiling)。下图能更清晰的展示这个逻辑,最终的结果是紫色部分,需要一个粗蓝色的行,和一个细红色的列。

宏观视角介绍完了,我们再回到微观视角:一个 thread 到底在干什么。线程的 inner loop 从 Bs 取一个元素,然后分别跟矩阵 A 的 8 个列相乘,暂存到 registers 中。
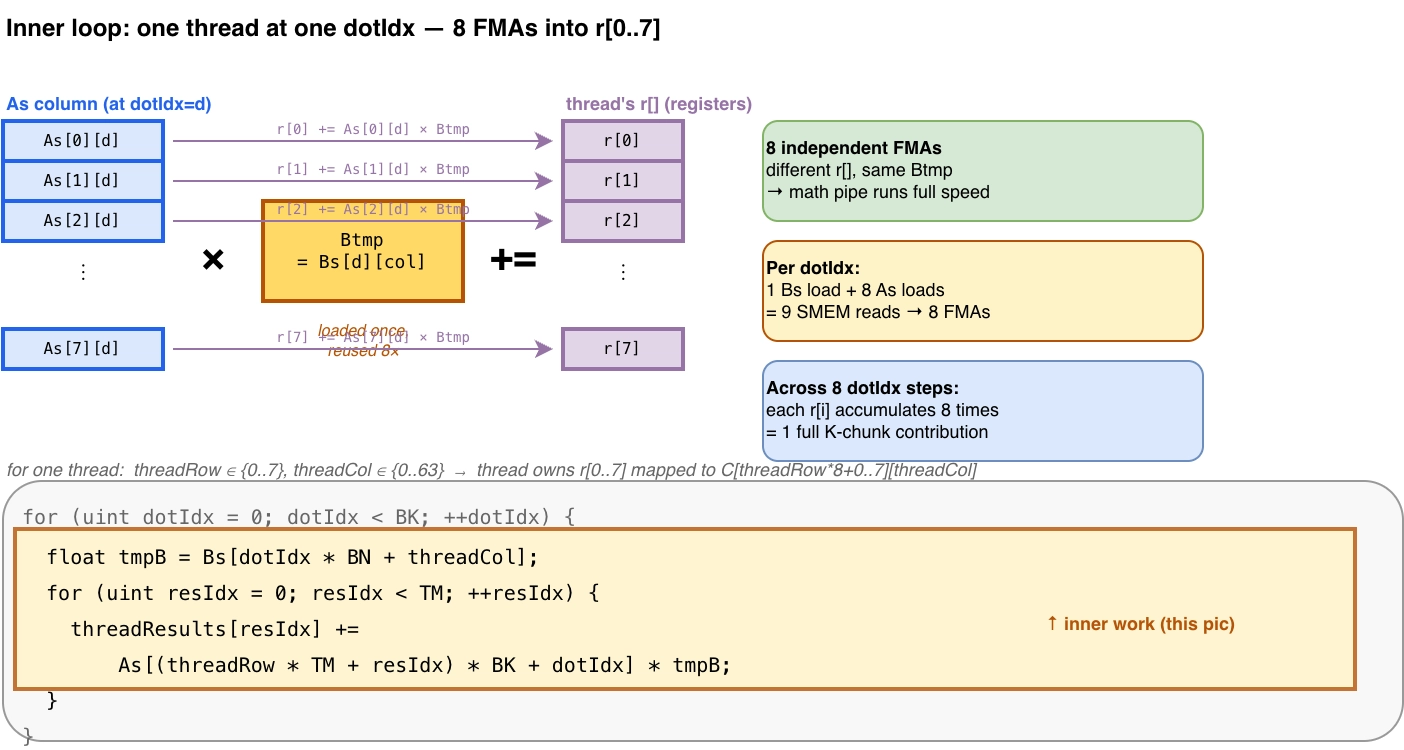
Outer loop 在 As 方向向右移动,Bs 方向向下移动。在我们的例子中,整个过程一共移动 8 次,然后继续执行 inner loop。

完成全部 8 次移动,意味着 As 和 Bs 的全部数据已经用完,线程跳回到最开始,重新填充新的数据到 As 和 Bs 中。
开头提到,kernel 3 的 SMEM/FMA 的比值是 2。Kernel 4 的情况是,读 1 次 Bs 和 8 次 As,进行了共计 8 次 FMA 计算,最终的比值是 1.1,下降了约一半。
实验结果
4092 size 可以跑出1929.5 GFLOPS 的性能,性能达成率 ~23.70%,比 kernel 3 快了 ~2.12x。
| Size | Average (s) | GFLOPS |
|---|---|---|
| 128 | 0.000045 | 92.9 |
| 256 | 0.000082 | 408.9 |
| 512 | 0.000377 | 712.6 |
| 1024 | 0.002353 | 912.5 |
| 4092 | 0.071021 | 1929.5 |
Kernel 5: 2D Threadtiling
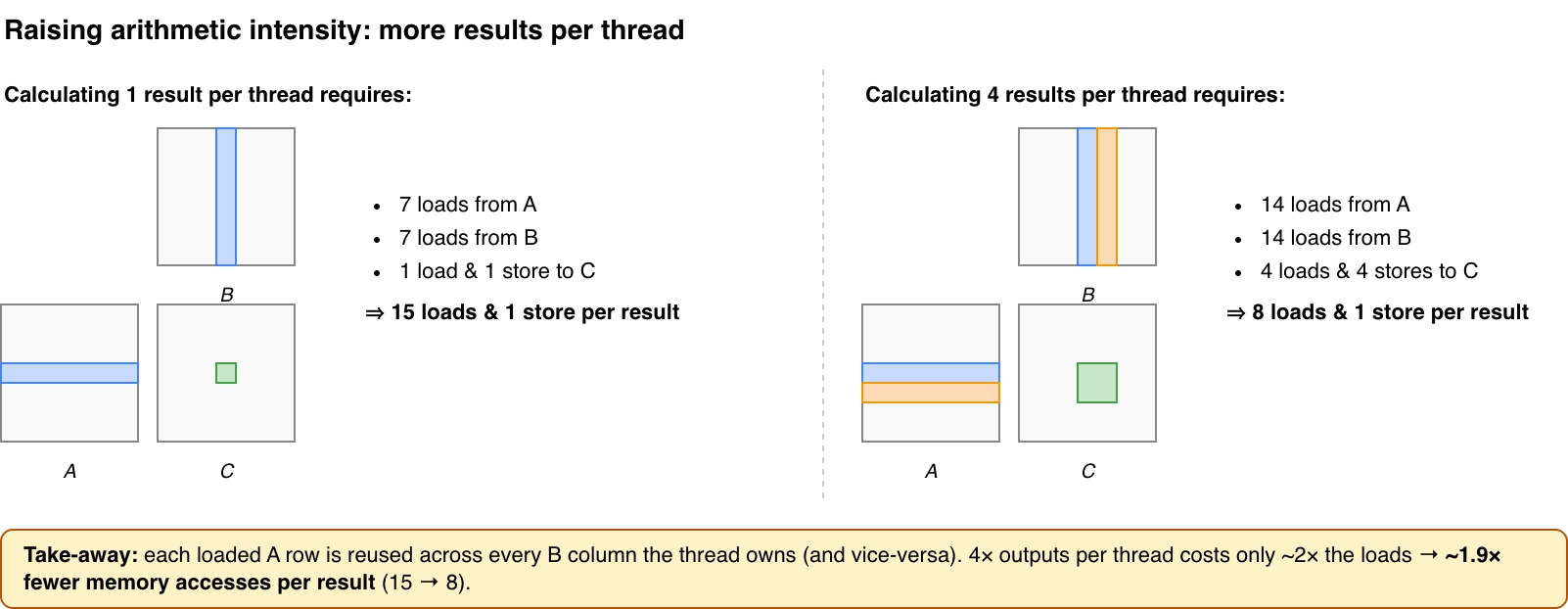
改进思路
我们的优化目标是提升计算强度(Arithmetic Intensity),其中一个思路是让 thread 承担更多的计算任务。下图举了一个简单的例子,左边 1 个 thread 计算矩阵 C 的一个元素,对应 15 次 loads 和 1 次 store,右边 1 个 thread 计算 4 个结果,每个结果对应 8 次 loads 和 1 次 store。
实现代码
Kernel 代码
float threadResults[TM * TN] = {0.0f};
float regM[TM] = {0.0f};
float regN[TN] = {0.0f};
for (uint bkIdx = 0; bkIdx < K; bkIdx += BK) {
for (uint loadOffset = 0; loadOffset < BM; loadOffset += strideA) {
As[(innerRowA + loadOffset) * BK + innerColA] =
A[(innerRowA + loadOffset) * K + innerColA];
}
for (uint loadOffset = 0; loadOffset < BK; loadOffset += strideB) {
Bs[(innerRowB + loadOffset) * BN + innerColB] =
B[(innerRowB + loadOffset) * N + innerColB];
}
__syncthreads();
A += BK;
B += BK * N;
for (uint dotIdx = 0; dotIdx < BK; ++dotIdx) {
for (uint i = 0; i < TM; ++i) {
regM[i] = As[(threadRow * TM + i) * BK + dotIdx];
}
for (uint i = 0; i < TN; ++i) {
regN[i] = Bs[dotIdx * BN + threadCol * TN + i];
}
for (uint resIdxM = 0; resIdxM < TM; ++resIdxM) {
for (uint resIdxN = 0; resIdxN < TN; ++resIdxN) {
threadResults[resIdxM * TN + resIdxN] +=
regM[resIdxM] * regN[resIdxN];
}
}
}
__syncthreads();
}
启动 kernel,现在只需要 256 个线程了,矩阵 C tile 进一步被放大为了 (128, 128)。
void run_sgemm_2d_blocktiling(int M, int N, int K, float alpha, float *A,
float *B, float beta, float *C) {
const uint BK = 8;
const uint TM = 8;
const uint TN = 8;
const uint BM = 128;
const uint BN = 128;
dim3 gridDim((N + BN - 1) / BN, (M + BM - 1) / BM);
dim3 blockDim((BM * BN) / (TM * TN));
sgemm2DBlocktiling<BM, BN, BK, TM, TN>
<<<gridDim, blockDim>>>(M, N, K, alpha, A, B, beta, C);
}
As 和 Bs 的容量是 (128, 8),需要 4 轮才可以将数据从 GMEM 拷贝到 SMEM 中(图中 inner loop)。每次进行完一次运算后,outer loop 会分别在矩阵 A 向右和矩阵 B 向下移动。
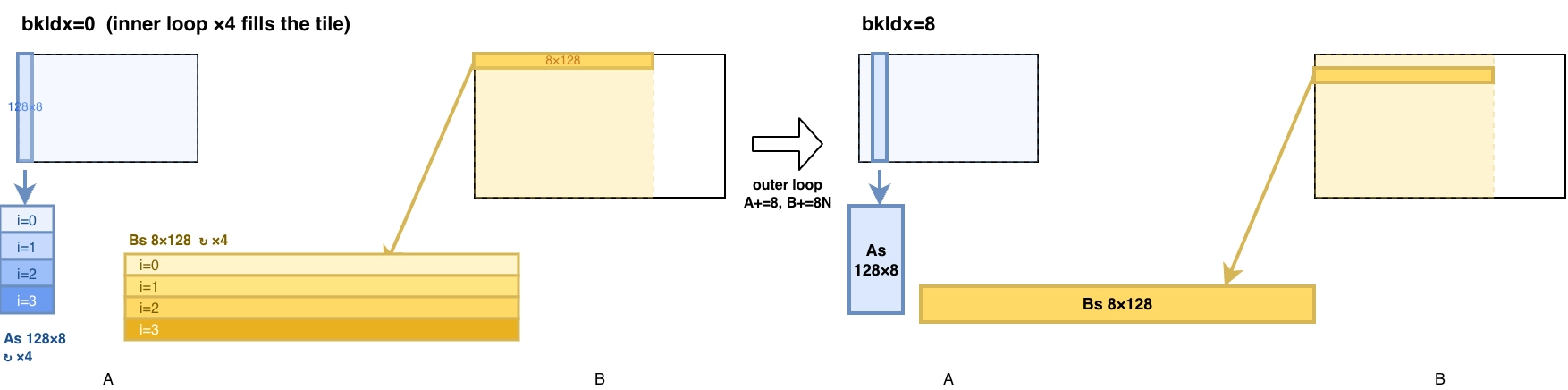
对比 kernel 4,不同点在于一个 thread 计算 8 个 cols,共计计算 64 个矩阵 C 元素。回看代码,与 kernel 4 的区别是加载矩阵 A 的相邻列元素到寄存器 regM 后,连续加载矩阵 B 的相邻行元素到寄存器 regN,最后在双层循环中计算 FMA,将结果暂存在 threadResults 寄存器中。

Kernel 5 每从 SMEM 加载 16 次,可以计算 64 次,因此 SMEM/FMA 比值进一步降低到了 0.25。
实验结果
4092 size 可以跑出 2729.1 GFLOPS 的性能,性能达成率 ~33.52%,比 kernel 4 快了 ~1.41x。
| Size | Average (s) | GFLOPS |
|---|---|---|
| 128 | 0.000144 | 29.2 |
| 256 | 0.000246 | 136.2 |
| 512 | 0.000452 | 594.2 |
| 1024 | 0.002310 | 929.7 |
| 4092 | 0.050214 | 2729.1 |
Kernel 6: Vectorize SMEM and GMEM Access
Vectorize
Vectorize 指利用 float4 类型连续加载 4 个 32B 的 floats,这跟 coalescing 有点相似,本质上都是加载连续数据的优化,但是它们面向的场景不同:
- Coalescing 是 warp 内的相邻线程读写相邻内容,warp scheduler 会组合多个 load 为一个大 load
- Vectorize 是指一个 thread 连续加载 4 个 floats 共计 128B。
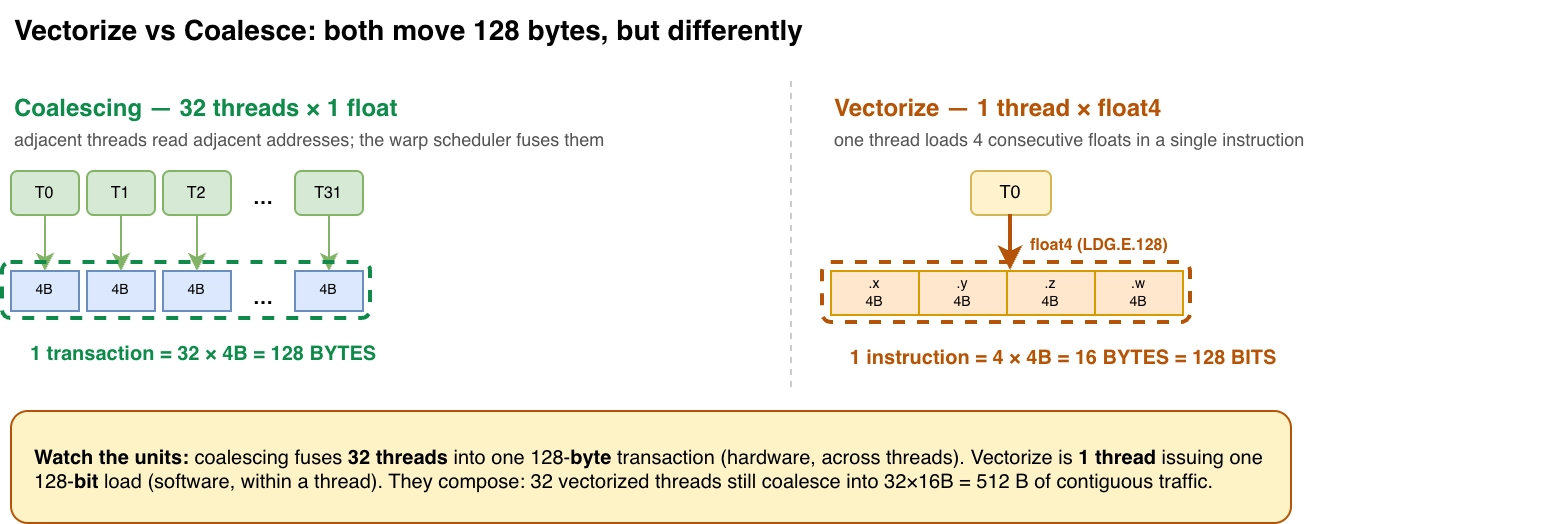
实现代码
Kernel 实现
__shared__ float As[BM * BK];
__shared__ float Bs[BK * BN];
float threadResults[TM * TN] = {0.0f};
float regM[TM] = {0.0f};
float regN[TN] = {0.0f};
for (uint bkIdx = 0; bkIdx < K; bkIdx += BK) {
const float4 aLoad =
reinterpret_cast<const float4 *>(&A[innerRowA * K + innerColA * 4])[0];
As[(innerColA * 4 + 0) * BM + innerRowA] = aLoad.x;
As[(innerColA * 4 + 1) * BM + innerRowA] = aLoad.y;
As[(innerColA * 4 + 2) * BM + innerRowA] = aLoad.z;
As[(innerColA * 4 + 3) * BM + innerRowA] = aLoad.w;
reinterpret_cast<float4 *>(&Bs[innerRowB * BN + innerColB * 4])[0] =
reinterpret_cast<const float4 *>(
&B[innerRowB * N + innerColB * 4])[0];
__syncthreads();
A += BK;
B += BK * N;
for (uint dotIdx = 0; dotIdx < BK; ++dotIdx) {
for (uint i = 0; i < TM; ++i) {
regM[i] = As[dotIdx * BM + threadRow * TM + i];
}
for (uint i = 0; i < TN; ++i) {
regN[i] = Bs[dotIdx * BN + threadCol * TN + i];
}
for (uint resIdxM = 0; resIdxM < TM; ++resIdxM) {
for (uint resIdxN = 0; resIdxN < TN; ++resIdxN) {
threadResults[resIdxM * TN + resIdxN] +=
regM[resIdxM] * regN[resIdxN];
}
}
}
__syncthreads();
}
启动 kernel,各项参数与 kernel 5 保持一致
void run_sgemm_vectorize(int M, int N, int K, float alpha, float *A, float *B,
float beta, float *C) {
const uint BK = 8;
const uint TM = 8;
const uint TN = 8;
const uint BM = 128;
const uint BN = 128;
dim3 gridDim((N + BN - 1) / BN, (M + BM - 1) / BM);
dim3 blockDim((BM * BN) / (TM * TN));
sgemmVectorize<BM, BN, BK, TM, TN>
<<<gridDim, blockDim>>>(M, N, K, alpha, A, B, beta, C);
}
从实现上来说,大部分与 kernel 5 保持一致,唯一的区别是用了 float4 强制加载连续 4 个 floats。除此之外,矩阵 A 从 GMEM 加载到 SMEM 过程中,多了一次矩阵转置的操作。为什么?下图的左半边是矩阵 A 的原始形状,之前的 kernels 都是原封不动的拷贝过来,在计算的时候会取 As 中的列元素,这导致无法在 SMEM 中使用 float4 向量化加载的操作。
想要在 GMEM 实现向量化必须要用 float4 类型,编译器不会像 coalescing 一样自动帮你优化,原因是底层的汇编指令是 LDG.E.128,它要求地址必须要 16-byte aligned。比如 float4 是 16-byte aligned,float 是 4-byte aligned。创建一个 float 数组,类型是 float*,编译器不知道里面有几个元素,因此你必须显式地转换类型为 float4,使 compiler 确信这个操作是安全的。
SMEM 是被 compiler 管理的,compiler 根据上面从 GMEM 的操作,知道这是一个 16-byte aligned 的数据,因此无需任何显式转换就可以实现向量化读取的功能。
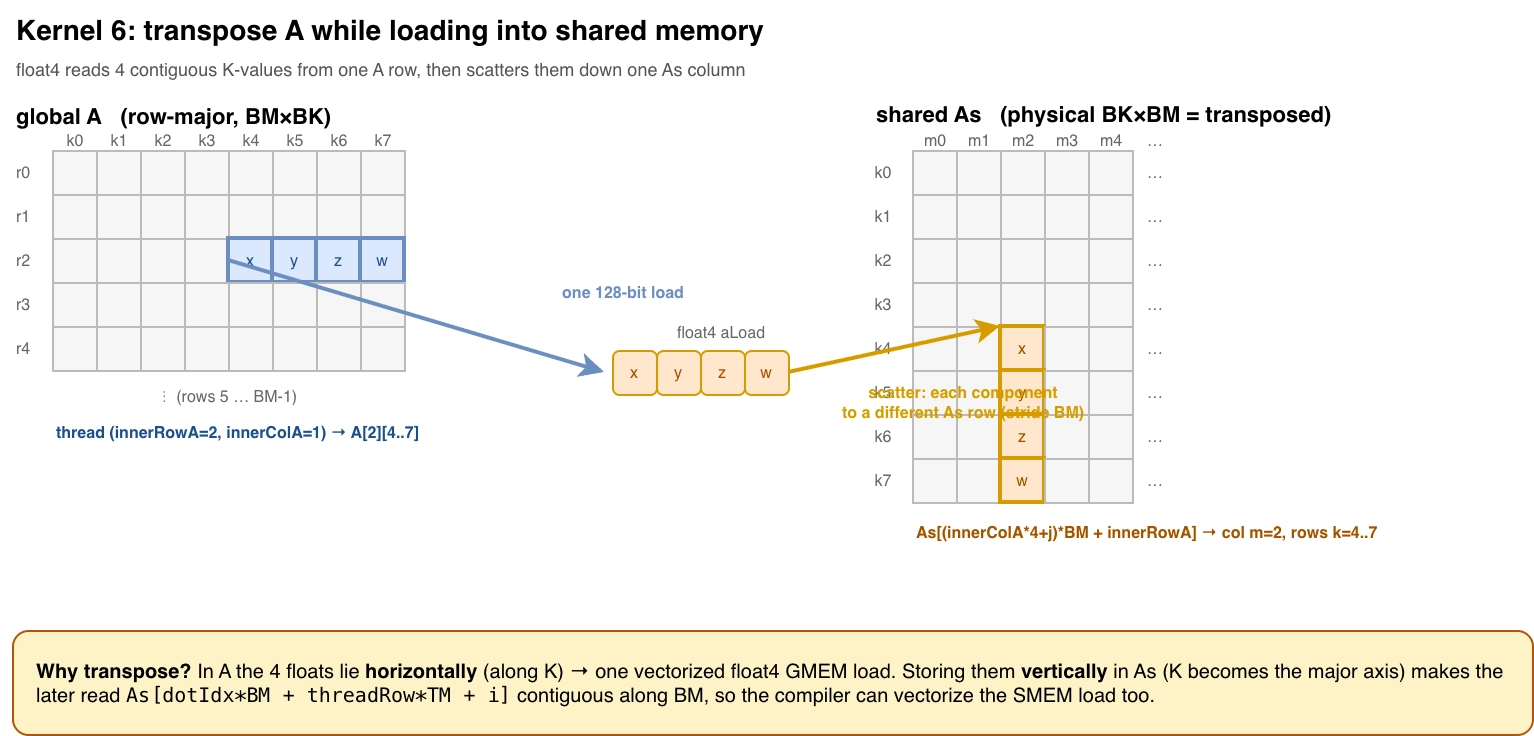
实验结果
P.S.
float4必须要 16-byte aligned,所以需要把测试的尺寸从 4092 提升到 4096。
4096 size 可以跑出 3971.3 GFLOPS 的性能,性能达成率 ~48.78%,比 kernel 5 快了 ~1.46x。
| Size | Average (s) | GFLOPS |
|---|---|---|
| 128 | 0.000095 | 44.4 |
| 256 | 0.000172 | 195.4 |
| 512 | 0.000330 | 814.1 |
| 1024 | 0.001325 | 1620.3 |
| 4092 | 0.034608 | 3971.3 |
Kernel 10: Warptiling
Warptiling
Tiling 的含义是需要从两个维度理解:计算并行和数据重用。
- Blocktiling 是指 SM 之间并发的计算各自的 C tile,而且数据读到 SMEM 中被重用。因此从这个意义上出发,kernel 1 和 kernel 2 都不能称之为 blocktiling,kernel 3 可以。
- Threadtiling 是指 threads 之间并发计算各自的 tile(1D tile 是
M*1规格的,2D tile 是M*N规格的),数据读到 regs 中被重用。
Block 和 thread 都有对应的硬件,也都可以在 CUDA 中被定义。Warp 同样有对应的硬件,只是不体现在 CUDA 代码中。SM 的硬件结构如下所示,内部包含了 4 个 warp schedulers,这就是 warp 的硬件。
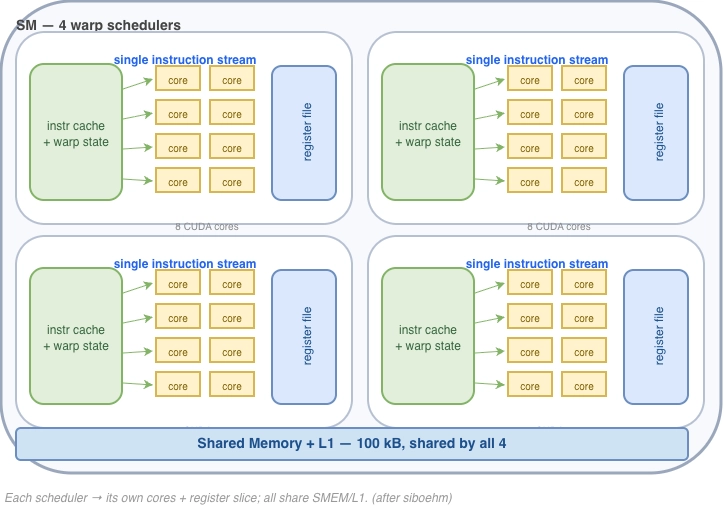
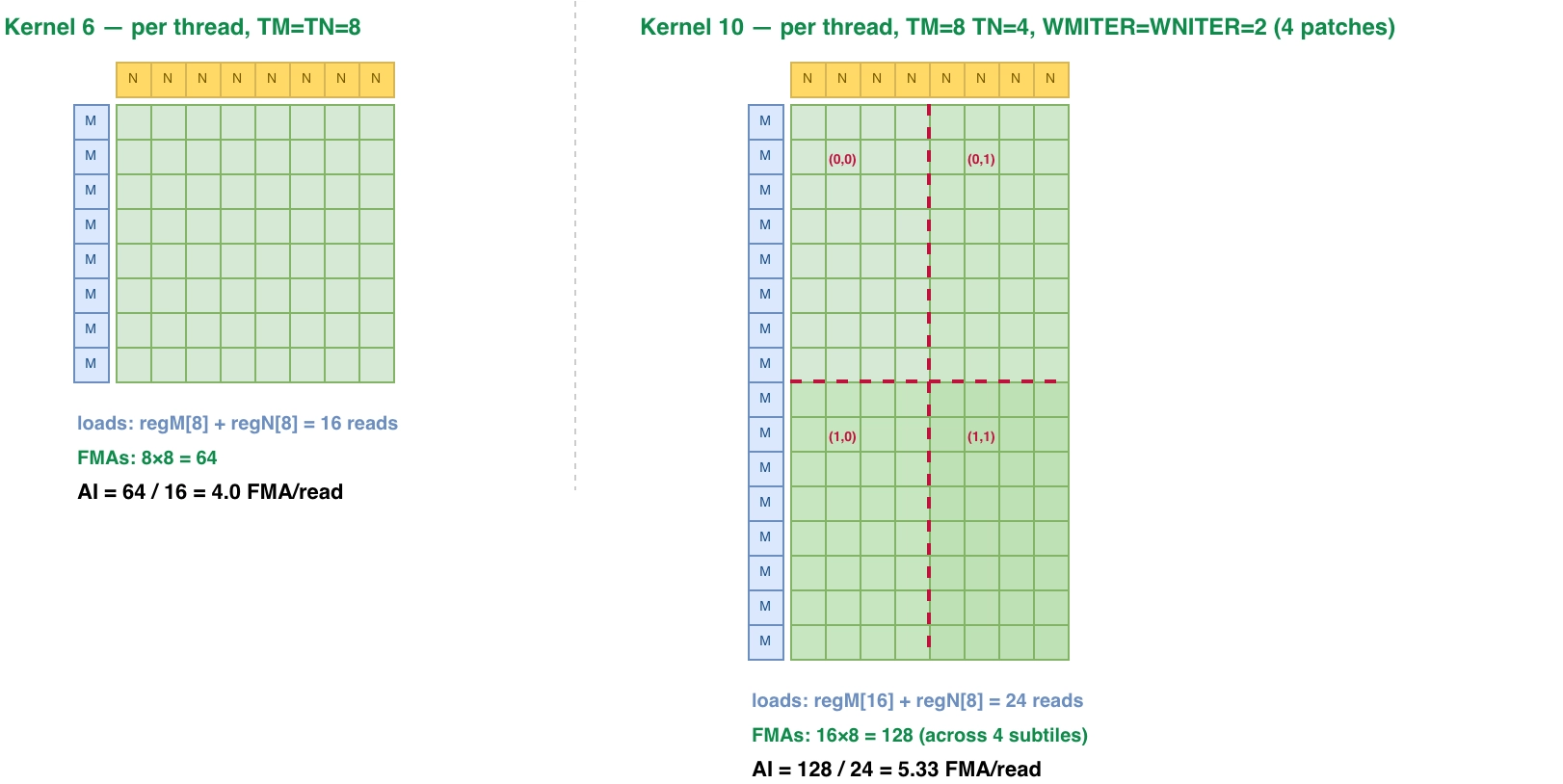
Warptiling 是在 thread 内占用了更多的寄存器,实现了更多次数的 FMA 计算。下图展示了其原理。左边是 kernel 6 不支持 warptiling,thread 计算完这个 64 个结果之后,寄存器 regM 和 regN就被清空了。Kernel 10 的方案是每个 thread regM 扩大两倍(数据重用),分 4 次计算其中一个 patch:
- time 0 计算图中
patch (0, 0)需要使用regM[0..7]和regN[0..3] - time 1 计算图中
patch (0, 1)需要使用regM[0..7]和regN[4..7](重用regM[0..7]) - time 0 计算图中
patch (1, 0)需要使用regM[8..13]和regN[0..3](重用regN[0..3]) - time 1 计算图中
patch (1, 1)需要使用regM[8..13]和regN[4..7](重用regM[8..13])
最终的效果,kernel 6 从 SMEM 读 16 个数据到寄存器中,计算 64 次,SMEM/FMA 的比值是 4,而 kernel 10 的这项比值可以达到 5.33。
代码实现
实现的过于复杂了,先跳过吧
实验结果
4096 size 可以跑出 4704.6 GFLOPS 的性能,性能达成率 ~57.79%,比 kernel 6 快了 ~1.18x。
| Size | Average (s) | GFLOPS |
|---|---|---|
| 128 | 0.000092 | 45.5 |
| 256 | 0.000164 | 204.1 |
| 512 | 0.000310 | 865.1 |
| 1024 | 0.001171 | 1834.3 |
| 4096 | 0.029214 | 4704.6 |
结尾
好长的文章,终于到结尾了,说明一下中间 kernel 空缺的问题吧。中间漏掉的 kernel 7 和 kernel 8 解决的是 bank conflict 的问题,通过重映射(remap)或者让数组空出来几位,目标让 stride 不能是 32 的倍数就可以了,逻辑上简单但是代码写起来复杂(我说的是 kernel 7),所以一并跳过了。Kernel 9 就更是纯工程了,主要是将超参数参数化,方便通过脚本寻找最优解,作者也说了在 A6000 上,用什么 BM、BM 等等效果最好,但是他没法解释原因,所以跳过。
最后的最后,放一个 cuBLAS 的 benchmark 结果,在 4096 这个规格下居然还比 NVIDIA 特调的 kernel 效果还好,有点意外。
| Size | Average (s) | GFLOPS |
|---|---|---|
| 128 | 0.000121 | 34.7 |
| 256 | 0.000111 | 301.5 |
| 512 | 0.000135 | 1988.1 |
| 1024 | 0.000829 | 2589.7 |
| 4096 | 0.031169 | 4409.5 |