WIP: I/O 多路复用: 从入门到放弃(一)
背景

.. toc::
最近在学习 k8s 的控制器模式时,作者最后有个灵魂一问:控制器模式和事件驱动的不同是什么?有些人答曰是 select 和 epoll 的差别,也有人答曰事件驱动是一次性的、被动的,控制器模式是主动的。我呢,越听越迷糊,时隔半年又看到 epoll,我竟一点都想不起来它的原理,所以我这次一定要把它搞明白,这就是我写这篇文章的初衷。这篇文章将从根上开始谈起,NIC(网卡)和内核、I/O 多路复用、select & epoll、事件驱动设计模式…
废话少说,Let's Go!
一个 TCP 连接是一种特殊的 I/O 资源,在 Linux 中都是依赖于文件描述符(fd)处理 I/O,也就是一个 TCP 连接对应一个 fd。[1]
I/O 事件
I/O 事件包含可读和可写两种。
- 可读事件是指内核缓冲区非空,用户可以从缓冲区中读数据;
- 可写事件是指内核缓冲区不满,用户可以向缓冲区中写数据。
NIC & Kernel
I/O 事件为什么必须要内核的参与?用户进程不能直接处理内核请求吗?
不行,Linux 系统出于安全考虑,涉及到与硬件交互的操作必须要由内核处理,在网络 I/O 中涉及到的硬件是网卡(NIC)。那么 NIC 与 kernel 是如何互动的呢?[2]
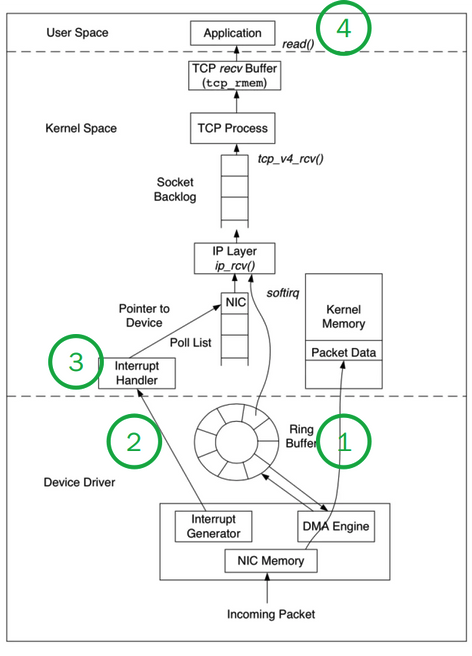
- NIC 接收到数据,通过 DMA 方式写入内存(Ring Buffer 和 sk_buff);
- NIC 发出中断请求(IRQ),告诉内核有新的数据过来了;
- Linux 内核响应中断,系统切换为内核态,处理 Interrupt Handler,从 RingBuffer 拿出一个 Packet, 并处理协议栈,填充 Socket 并交给用户进程;
- 系统切换为用户态,用户进程处理数据内容。
数据包到达后需要内核填充 Socket 交给用户。
非阻塞 I/O & 阻塞 I/O
非阻塞 I/O(Non-Block I/O)和阻塞 I/O 都是同步的,他们的区别在于是否占用 CPU 时间。
非阻塞 I/O 非常简单,进程等不到数据就通过一个 for loop 无限循环的等下去,直到数据准备好。只要数据没准备好 CPU 就一直进行轮询操作,最终导致 CPU 有效利用率降低。
为什么会导致 CPU 有效利用率低?
因为 I/O 任务的速度太慢,跟不上 CPU 的速度,以网络 I/O 为例,数据包传递的延迟一般是 ms 级,而 CPU 处理一次任务事件一般是 ns 级,数据不全时 CPU 的轮询操作属于无意义的工作且时间过长,CPU 有效利用率自然就显著降低了。
我们可以想到:如果数据不全的时候让进程阻塞,等内核确认数据可用时再把进程唤醒,这样就避免了 CPU 轮询导致的空耗问题了,这就是阻塞 I/O 的初衷。
如果进程被标记为阻塞的进程,进程调度器不会给它分配 CPU 时间。从进程的角度,因为缺少数据而阻塞等待(同步)。从全局的角度,等待数据的进程不再占用 CPU 时间,其他任务可以获得更多的 CPU 时间,CPU 利用率提高了。
那么被阻塞的进程被谁唤醒?什么时候才能被唤醒呢?
被内核唤醒,因为只有内核才知道哪个进程的数据准备好了。众所周知一个端口对应着一个进程,内核可以根据 TCP 包中的端口号识别当前数据包是哪个进程的,然后唤醒对应进程。
至此,一个进程阻塞和唤醒形成了闭环(没错,就是一个完美的闭环🤪)。
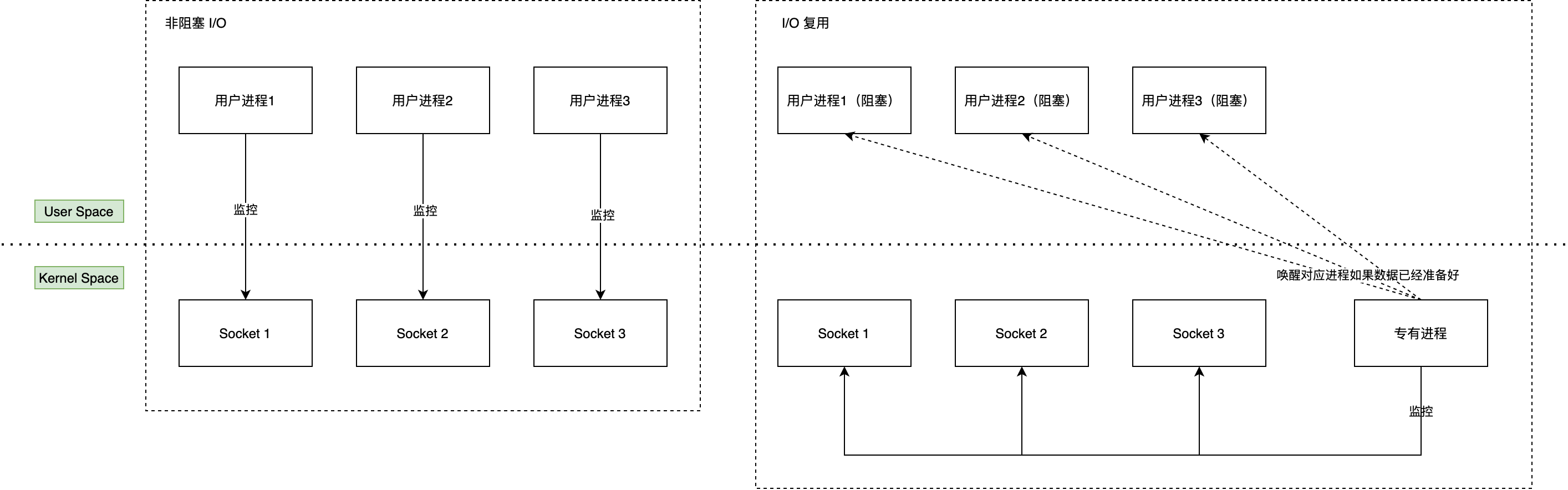
如果想使用非阻塞 I/O,内核就必须拥有同时监控多个 socket 的能力,所以 I/O 多路复用登上历史舞台,又因为实现方式的差异,导致执行效率显著不同,他们之间的实现细节将在下一篇文章中详细讨论。
OS: 阻塞原理
To Be Supplemented...
Socket
To Be Supplemented...